정부가 '데이터 강국' 청사진을 마련했다. '데이터를 가장 안전하게 잘 쓰는 나라'를 비전으로 삼았다. 내놓은 실행방안은 30여가지나 된다.
이에 대해 민간은 "실행력이 중요하고 예산이 뒤따라야 한다"는 반응을 내놨다.
대책에 따르면, 우선 700여 공공기관이 보유한 공공 데이터를 다음달 말까지 전수 조사, 공공 데이터 현황을 보여주는 국가데이터 맵을 연말까지 만든다.
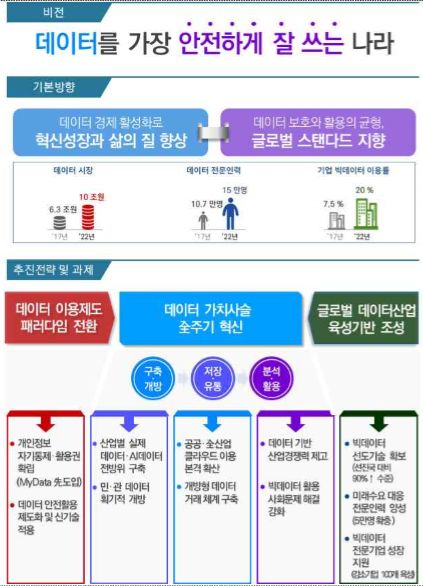
향후 5년간 데이터 전문 인력도 5만명 정도를 양성한다. 당장 내년부터 데이터 분석 국가기술자격제도가 신설, 운영된다. 데이터 강소기업도 현재 30곳에서 100곳으로 늘린다. 국내 데이터 시장 규모도 지난해 6조2973억 원에서 2020년 7조 8450억 원으로 늘린다.
누구나 데이터를 한 곳에서 쉽고 빠르게 등록, 검색, 거래할 수 있게 민간과 공공을 연계한 데이터 거래 기반도 연내 만든다. 날씨, 지도, 기업정보 등을 보유한 기업이 협력해 데이터를 공유 및 판매하는 데이터 거래소를 설립하면 초기 단계를 지원한다. 민간 주도 데이터 거래를 촉진하기 위해서다.
공공성이 높은 민간데이터(코스콤 주식시세 등)는 연구 및 창업 목적시 부담없이 활용할 수 있게 중재 및 개방을 확대한다. 통신, 금융, 유통 등 민간의 자율적 데이터 개방도 유도한다.
데이터 이용 패러다임을 전환한 '마이데이터(MyData)' 시범 사업도 연내 시행한다. 이는 개인정보 관련 법 개정 없이도 시행이 가능하다. 데이터 반출은 안되고 분석 및 인공지능(AI) 개발 결과만 내보내는 '데이터 안심존'도 구축한다.
이들 안은 26일 대통령 직속 4차산업혁명위원회(이하 4차위, 위원장 장병규)가 광화문 회의실에서 개최한 제7차 회의에서 '데이터 산업 활성화 전략'이란 이름으로 심의, 의결됐다.
과기정통부는 이번 '데이터 산업 활성화 전략'이 4차 산업혁명 핵심기반인 초연결 지능화 인프라 구현을 위한 DNA(Data-Network-AI) 전략의 데이터(D)에 관한 것이라고 설명했다. 앞서 제3차 회의(17년 12월)에서 의결한 '초연결 지능형 네트워크 구축방안(N)'과 제6차 회의(18년 5월)에서 의결한 '인공지능 R&D 전략(A)'에 이은 것으로, 이번 의결로 4차 산업혁명에 대응하는 종합적인 DNA 대책이 마련됐다고 덧붙였다.
이번에 의결한 안은 크게 ▲글로벌 데이터 산업 육성 기반 조성 ▲데이터이용제도 패러다임 전환 ▲데이터 가치 사슬 전주기 혁신 등 3가지로 구성됐다. 과기정통부는 이러한 정책 노력이 성공을 거두면 현재 세계 최고(미국) 대비 76% 정도인 빅데이터 기술 수준이 오는 2022년 90% 이상으로 올라갈 것으로 전망했다.
■글로벌 데이터산업 육성 기반 조성
데이터산업 미래 수용에 대응하기 위해 향후 5년간 청년고급인재와 실무 인력 중심으로 빅데이터 전문 인력 5만명을 양성한다. 청년 일자리와 연계해 빅데이터 전문 교육 프로그램을 지원하고 데이터 분석 고급인재 양성을 위해 관련된 대학 전공과 연구센터 운영도 확대한다.
국가공인 데이터 자격제도를 지속적으로 활성화하고 내년부터 데이터 분석 국가기술자격제도(빅데이터 분석사)를 신설해 운영한다. 지난해까지 설계(데이터 아키텍처)와 개발(SQL), 분석(데이터 분석) 분야에서 약 1만2000명을 배출했다.
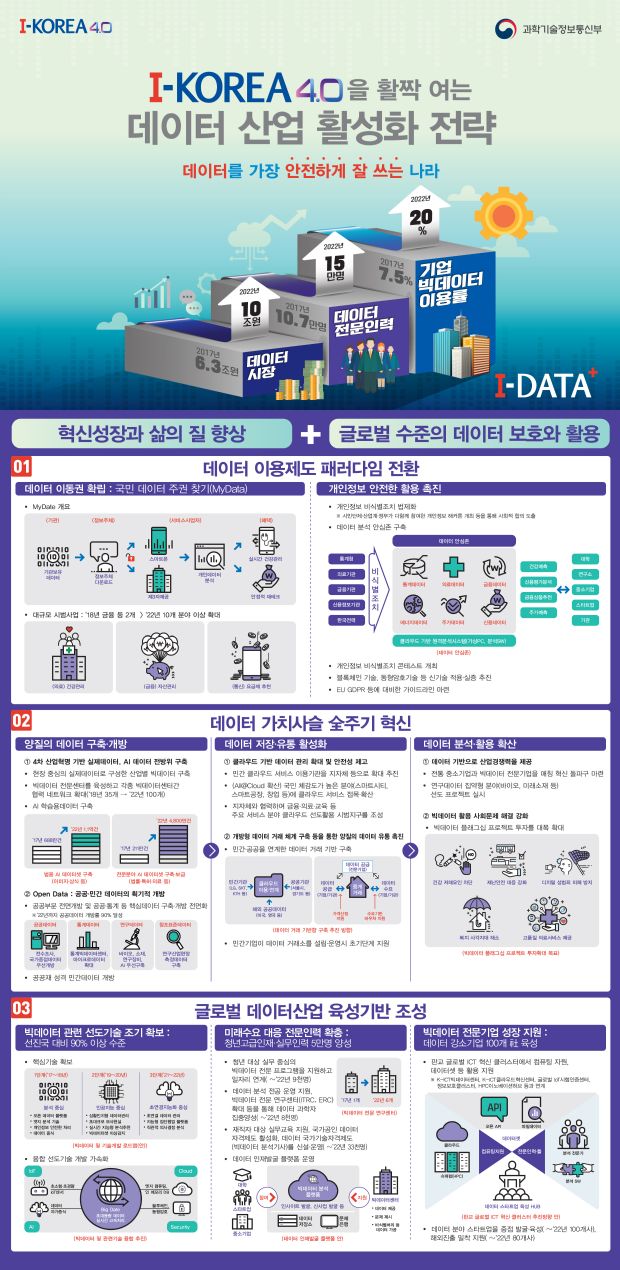
빅데이터 전문 기업 성장에 필요한 컴퓨팅 자원, 맞춤형 사업 등을 지원, 데이터 강소기업 100곳도 육성한다. 현재는 약 30곳 정도다. 또 구글 캐글 방식을 벤치마킹해 학계와 스타트업, 연구기관 등이 참여해 데이터를 연계 분석, 새로운 가치를 찾아내는 데이터 인재발굴 플랫폼도 구축한다.
컴퓨팅 자원, 데이터셋이 집적한 판교 글로벌 ICT 혁신 클러스터를 글로벌 수준으로 고도화, 스타트업의 활용을 집중 지원한다.
'K글로벌 DB스타' 등 데이터 스타트업 대상 맞춤형 지원사업을 지속적으로 확대하고 유망 데이터 기업의 솔루션 현지화와 마케팅을 지원, 해외 진출을 촉진한다.
■데이터 이용 패러다임 전환
정보주체인 개인이 자신의 데이터를 스스로 통제 및 활용하는 쪽으로 데이터 이용 패러다임을 전환한다. 이의 일환으로 개인정보 관련 법 개정 없이도 가능한 '마이데이터'제를 시범 사업으로 시행한다.
이는 국가기관이 보유한 나에 대한 정보(건강 검진 등)나 내가 제공한 개인 정보(카드사용 내역, 통신 사용량 등)를 내가 활용하는 것이다. 올해 금융 등 2개 분야를 시범사업으로 하고, 2022년에는 10개 분야 이상으로 확대한다.
미국에는 '블루버튼'이라는 의료 분야 개인 데이터 다운로드 서비스가 있다. 약 1만6000개 기관이 '블루버튼' 기능을 지원하고, 약 300만명이 의료정보를 내려 받았다.
개인 정보의 안전한 활용도 촉진한다. 이를 위해 데이터 반출은 안되지만 분석 및 AI 개발은 가능한 '데이터 안심존'을 구축해 내년부터 제공한다. 개인정보 해커톤 같은 사회적 합의를 바탕으로 개인정보보호법, 위치정보법 같은 법 개정도 추진한다.
데이터 보안성이 높은 블록체인과 동형암호의 실증 사업을 올해부터 2020년까지 추진한다. 개인정보 비식별조치 콘테스트를 KISA 주관으로 올해 개최하고 블록체인 기술지원센터도 설치한다. 데이터 주권을 강화하기 위한 제도도 정비, 개인정보가 해외서도 안전하게 보호되도록 국외 이전 중단 명령권을 올해 신설한다.

■데이터 가치 사슬 전주기 혁신
데이터 구축에서 시작해 저장 및 유통, 분석 및 활용 등으로 이어지는 데이터 전 과정을 혁신, 양질의 데이터를 구축해 개방한다.
공공 및 민간 데이터의 획기적 개방을 위해 모든 공공 데이터는 원시 데이터(raw data) 형태로 최대한 모으고, 이중 민간 수요가 높은 데이터를 국가중점데이터로 선정(2017년 48개서 2022년 128개로)해 조기에 개방한다.
의료, 제조, 농수산업, 도시, 교통, 환경 등 6개 산업별 빅데이터 전문센터를 육성하고, 각 빅데이터센터간 협력네트워크를 구축한다.
국내 인공지능 산업의 비약적 발전을 위해 범용(이미지, 상식 등), 전문(법률, 특허, 의료 등) 분야 AI데이터셋을 수요 중심으로 단계적으로 구축해 보급한다. 범용 데이터셋은 2017년 688만건에서 2022년 1억1000만건으로, 전문데이터셋은 2017년 211만건에서 2022년 4800만건으로 각각 늘린다.
국가 안보와 개인정보를 제외한 공공데이터를 개방하고 700여 공공기관이 보유한 데이터를 8월말까지 전수 조사, 국가데이터맵을 연말까지 만든다.
기계 학습이 용이하게 개방한 공공데이터는 오픈 포맷(3단계) 비중을 지난해 78.8%에서 올해 85%로 높인다. 개방 표준 서식은 지난해 109종에서 올해 200종으로 늘린다. 공공기관 품질관리 수준 평가제도 올해 중앙행정기관을 대상으로 시행하고 내년에 지자체, 2020년 공공기관으로 확대한다.
유통, 금융 등 민간의 자율적 데이터 개방을 유도하고, 공공성이 높은 민간데이터(코스콤 주식시세 등)는 하반기부터 연구 및 창업 목적시 부담없이 활용할 수 있게 중재 및 개방을 확대한다.
누구나 데이터를 한 곳에서 쉽고 빠르게 등록, 검색, 거래할 수 있도록 민간, 공공을 연계한 데이터 거래 기반을 연내 구축한다.
이를 위해 민간과 공공 데이터 포털을 연계해 개방형(오픈소스 기반 플랫폼)으로 고도화하고 국내외 주요 데이터 플랫폼을 연계한다. 데이터 가공 전문기업과 수요기업을 매칭해주고 초기시장 활성화를 위해 중소 및 스타트업에 데이터 바우처도 제공한다. 바우처를 통해 가공한 데이터는 상품으로 다시 등록 및 판매한다.
민간 주도 데이터 거래를 촉진하기 위해 데이터 상품(날씨, 지도, 기업정보 등) 기업들이 협력해 데이터를 공유 및판매하는 데이터 거래소를 설립해 운영할 경우 초기 단계를 지원한다. 중국의 경우 세계 최초로 민관 합작형태의 데이터 거래소 설립을 통해 공공 데이터 가공 및 판매에 나서고 있다.
■데이터산업 활성화 전략이 나온 배경은..,
데이터는 4차 산업혁명을 견인하는 핵심 동인이다. 세계 데이터 시장 규모는 IDC에 따르면 지난해 1508억 달러에서 오는 2020년 2100억 달러로 늘어난다. 세계 데이터량도 2016년 16제타바이트(ZB, 1ZB는 1조1000억 기가바이트)에서 2025년 163ZB로 폭증한다.
데이터 기반 가치 창출은 국가 및 기업의 혁신성장 수단이다. 선진국은 국가 경제의 지속 성장 및 일자리 창출을 위해 빅데이터 접목을 통한 주력산업 재도약과 혁신성장에 나서고 있다. 데이터가 기존 생산요소(자본, 노동)를 능가하는 경쟁 원천으로 부상했기 때문이다.
대규모 데이터를 보유하고 활용을 잘하는 기업이 시장 혁신을 주도하고 있는 형국이다. 이미 주요국은 미래 경쟁력을 좌우하는 데이터의 중요성을 인식, 데이터산업 활성화를 위한 전략 수립과 투자확대에 나서고 있다. 예컨대 미국은 2016년 빅데이터 연구개발 전략을 수립했고 EU도 지난해 데이터경제 육성 전략을 발표했다. 일본 역시 지난해 '소사이어티 5.0' 실현 데이터 활용 방안을 마련했고, 중국도 지난해 빅데이터산업 발전 계획을 수립했다.
이런 흐름과 달리 우리는 '데이터 후진국'이다. 세계적으로 엄격한 수준의 개인정보 규제를 가진 탓이다. 이 규제로 데이터 활용이 위축됐고, 데이터 보호 수준도 높지 못한게 현실이다. 데이터 구축, 유통, 활용 등 가치사슬 전반에 걸쳐 고품질 데이터가 부족하고 폐쇄적 유통구조, 산업 및 사회적 활용 저조 같은 한계에 직면했다.
4차산업혁명시대를 맞아 신제품, 신서비스 개발에 필수인 자율차, 스마트시티 등의 영역별 실제 데이터와 AI 학습용 데이터 구축도 미흡하다. 또 공공데이터 개방이 계속 이뤄져왔음에도 활용도가 높은 고부가 공공데이터는 양적으로 부족하고 품질도 낮다. 실제 올 3월 발표된 자료에 따르면 정확성 결여와 불일치, 중복 및 누락 같은 낮은 수준의 공공데이터 숫자가 한국은 25만개인데 반해 미국은 23만3천개, 영국은 4만4천개 밖에 안된다.
빅데이터의 핵심 인프라인 클라우드 이용률도 지난해 기준 우리나라는 12.9%로 OECD 33개 국가중 27위에 그쳤다. 여기에 개별 기업 중심의 제한적 데이터 유통과 거래제도 미비 등도 양질의 데이터 유통을 제한하고 있다.
데이터 분석 및 활용도 미흡한 수준이다. 데이터가 산업 및 사회 혁신의 촉매제임에도 산업적 활용은 아직 조치 단계다. 한국정보화진흥원(NIA)에 따르면 지난해 우리나라 전체 산업체의 빅데이터 이용률은 7.5%에 불과하다.
국민의 삶과 직결된 환경, 교통, 안전이슈 같은 사회 문제 해결에도 데이터 활용은 저조하다
기술 수준 역시 낮다. 세계 최고인 미국을 100으로 했을때 76 정도다. 반면 빅데이터 관련 연구개발 투자는 꾸준히 늘었다. 2016년 126억원에서 2017년 155억 원, 올해 176억 원이다. 기업이 필요로하는 전문인력도 부족하다.
관련기사
- "데이터 가두는 문서포맷, 4차산업혁명 걸림돌"2018.06.26
- 정부 "AI 등 신산업 공공데이터 전면 개방"2018.06.26
- 산업부, 빅데이터 구축으로 바이오 산업 키운다2018.06.26
- 데이터 세계의 황금 트라이앵글2018.06.26
케이데이터에 따르면 향후 3년간 빅데이터 분석가와 개발자 등 전문인력이 약 1만3000명 부족할 전망이다. 전문 기술을 보유한 스타트업도 부족하고, 글로벌 수준의 기술혁신 기업도 찾아보기 힘들다. 미 CRN사에 따르면 지난해 글로벌 100대 빅데이터 기술혁신 기업중 국내 기업은 하나도 없다. 알파인데이터랩스(Alpine Data Labs), 아마존,IBM 등 미국 기업이 대부분을 차지했다.
이재형 과기정통부 융합신신업과장은 "데이터 산업 활성화로 2022년 국내 데이터 시장은 10조원 규모 성장과 데이터 전문 인력 15만명 수준 확충, 기업의 빅데이터 이용률 20%로 향상 등의 효과가 기대된다"고 예상했다.