






세계 웹사이트 수백만 곳에 도입된 콘텐츠딜리버리네트워크(CDN) 서비스가 보안 사고를 냈다. 버그 때문에 CDN을 거쳐 간 고객사 웹페이지 내용을 뜻하지 않게 인터넷에 흘려보냈다.
회사측은 외부 제보를 받아 몇 시간만에 이 버그를 수정했다. 이를 지난달 23일 블로그에 공지했다. 인터넷 세상이 발칵 뒤집혔다. 버그를 고쳤지만 그 전 수개월간 민감한 정보가 대량 유출됐을지 모른단 우려가 불거졌다.
CDN 사업자 공지엔 버그 진단과 초기 대응 조치는 있었지만, 고객사가 피해 규모를 짐작할 정보가 없었다. 웬만한 인터넷 사용자 모두 잠재적 피해자일 수 있다는, 불안 여론이 사그러지지 않는 배경이었다.

지난 2010년 설립된 미국 스타트업 '클라우드플레어(Cloudflare)'얘기다. 사고를 낸 버그는 '클라우드블리드'라 불렸다. 기존 심각한 버그로 유명한 '하트블리드'에 빗댄 표현이다. 최악의 보안사고 기록을 경신할 분위기였다.
클라우드플레어 측은 수습에 나섰다. 자체 조사를 거쳐 이달초 고객사들의 위험을 자가 판단할 수 있는 기준과 잠정적인 피해 추정 규모를 제시했다. 당초 우려만큼 심각한 피해는 없다는 메시지였다.
클라우드플레어가 자사 버그로 인한 정보 유출 사고가 사상 최악일 수도 있다는 일각의 여론을 잠재울 수 있을까. 일명 클라우드블리드 사건으로 불리는 CDN 서비스 보안사고의 전말을 정리했다.
■ 급성장한 CDN, 구글 제보로 뒤늦게 버그 인지

클라우드플레어는 가격에 따라 기능을 차등화한 유무료 CDN 서비스를 제공한다. 이 서비스는 세계 인터넷 트래픽을 2014년 하반기 5%, 2016년 상반기 10%까지 처리할만큼 성장했다. 회사는 고객사로 우버(Uber), 핏비트(Fitbit), 오케이큐피드(OkCupid), 패스트메일(Fastmail), 디지털오션(DigitalOcean), 젠데스크(Zendesk), 유다시티(Udacity)를 맞아들였다. 고객 수도 지난해 9월 400만 곳, 최근 600만 곳으로 크게 늘었다.
그런데 최근 구글 정보보안담당 엔지니어 겸 '프로젝트제로' 팀 소속 취약점분석가인 타비스 오르만디(Tavis Ormandy)가 급성장세인 클라우드플레어 서비스에서 버그를 발견했다.
CDN은 웹사이트의 정보를 중개해 많은 방문자에게 빠르고 안정적으로 전달한다. 이를 위해 웹페이지를 효율적으로 처리하는 HTML 파서 기술을 쓴다. 파싱이라는 과정이다. 그런데 클라우드플레어 CDN에는 파싱 중 서버가 무작위로 메모리상의 엉뚱한 정보를 반환하는 버그가 있었다. 누군가의 이메일, 계정명, 비밀번호, 채팅 메시지같은 개인정보와 HTTP 쿠키, 인증 토큰 등의 대규모 유출됐을 우려가 불거졌다.
클라우드플레어는 지난달 18일 오르만디의 제보를 받고 대응에 나섰다. 존 그레이엄 커밍 클라우드플레어 최고기술책임자(CTO)가 지난달 23일 공식블로그를 통해 회사측의 버그 관련 상황 전말과 대응 방향을 밝혔다.
[☞원문: Incident report on memory leak caused by Cloudflare parser bug]
■ "HTML 파서 새걸로 바꾸다 생긴 버그…7시간만에 수정"
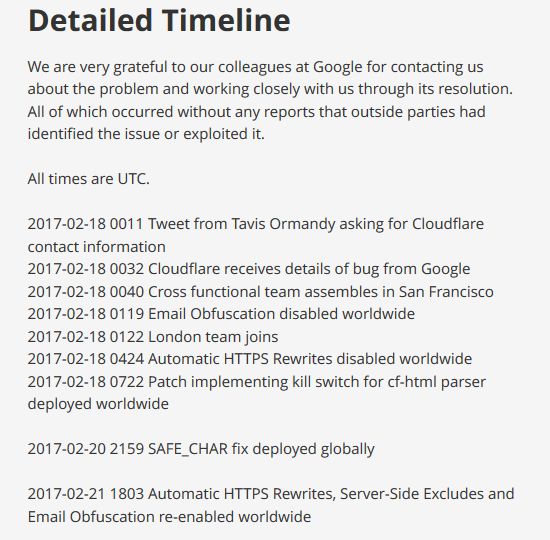
버그가 발생한 원인은 낡은 HTML 파서를 새 것으로 전환하는 과정에 있었다.
그레이엄 커밍 CTO는 클라우드플레어 서비스가 대부분 엣지서버를 거쳐 가는 HTML 페이지를 파싱 및 수정하는 동작에 의존하고 있다고 설명했다. 엣지서버는 페이지를 CDN에 최적 형태로 수정하기 위해 HTML을 읽고 파싱한다. 회사측은 서비스 초기 '레이젤(Ragel)' 기반으로 자체 개발한 파서를 쓰다가, 이후 HTML5 환경에 더 잘 맞는 'cf-html'이라는 스트리밍 파서로 이전하는 작업을 진행했다.
두 파서는 모두 NGINX 모듈로 구현됐다. HTML 응답을 포함한 버퍼(메모리 블록)를 파싱하고, 필요에 따라 수정하고, 다음 모듈로 버퍼를 건네 주는 동작을 했다. 이 버퍼를 건네 주는 동작이 문제였다. 다만 이는 기존 파서의 기반 기술인 레이젤이나, 새로 개발한 cf-html 파서의 자체 결함은 아니었다. cf-html 파서가 버퍼를 다루는 방식의 미세한 변화가 원인이었다는 게 회사측 설명이다.
클라우드플레어의 대응은 비교적 빨랐다. 제보를 받고 버그를 파악한 뒤 이런 동작을 하는 HTML 파서를 사용하는 마이너 기능 3가지를 즉시 서비스에서 내렸다.
그레이엄 커밍 CTO는 "이로써 더 이상 HTTP 요청에 메모리상의 엉뚱한 정보를 반환하는 동작은 하지 않게 됐다"며 "47분만에 최초 대응을 했고 버그를 수정해 전체 서비스에 적용하는 데 걸린 시간은 7시간 이내"였다고 설명했다.
그는 버그 동작이 활발했던 지난달 13일부터 18일 사이 기록을 검토한 결과, 정보 유출 빈도를 최대한 잡을 경우 HTTP 요청 330만건 당 1건 정도일 것이라고 추산했다. 전체 요청의 0.00003% 비중이었다.
■"민감한 정보 노출 가능성 남아…검색 캐시 소거"

하지만 클라우드플레어 고객사들이 덮어놓고 안심할 수는 없었다. 서비스 전체 규모 대비 유출된 데이터 크기가 작을 수는 있지만, 버그에 노출된 서비스가 뭐고 그런 기간이 언제부터 언제까지인지는 곧바로 파악되지 않았기 때문이었다.
그레이엄 커밍 CTO도 "유출된 메모리 내용에 클라우드플레어 고객 대상으로 처리 중이던 HTTP 요청이 존재했다는 사실이 더 우려스러운 점"이라며 "이는 보호돼야 할 정보가 노출됐을 수 있다는 뜻"이라고 썼다. 보호돼야 할 정보에는 HTTP 헤더, 비밀번호를 포함했을 수도 있는 POST 데이터 청크, API 콜에 대한 JSON, URI 파라미터, 쿠키, 이밖에 API 키와 OAuth 토큰처럼 민감한 인증 정보가 들어간다.
구글을 비롯한 다른 인터넷 검색서비스의 존재는 문제를 악화시킬 수 있었다. 검색엔진은 인터넷에서 검색되는 데이터를 긁어모아 사용자에게 빠르게 보여줄 수 있도록 캐시를 생성한다. 클라우드플레어의 파서 버그로 흘러나온 데이터가 구글같은 검색엔진의 정상적인 데이터 수집과 캐시 처리 동작에 포함돼 있으면, 민감한 정보가 계속 인터넷에 남아있게 된다.
클라우드플레어 측은 정보보안팀을 동원, URI값을 식별해 검색엔진에 캐시 데이터로 남아 있는 유출 정보를 찾아 소거 작업을 진행했다. 이들은 구글, 야후, 마이크로소프트(MS) 빙, 기타 검색엔진 서비스 업체들의 도움을 받아, 161개 고유 도메인이 포함된 고유 URI값 770개를 발견해 지웠다.
이 버그에 '클라우드블리드(CloudBleed)'라는 별칭이 붙었다. 미국 씨넷 보도에 따르면 당시 버그를 제보한 구글 엔지니어 오르만디가 농담삼아 쓴 표현이다. 3년전 대형 보안 이슈로 회자된 하트블리드(HeartBleed)만큼, 어쩌면 그보다 더 심각할 수 있다는 인식이 반영된 결과다. 이 별칭은 소셜미디어와 다수 IT매체를 통해 빠르게 확산됐다.
[☞미국 씨넷 원문: Uber, Fitbit, OkCupid info exposed by 'CloudBleed' flaw]
■잠정 판단 "버그 악용 흔적·민감 정보 유출 없어"
하트블리드는 SSL 표준을 오픈소스로 구현한 오픈SSL(OpenSSL) 소프트웨어의 서버 메모리 정보를 잘못 내보내는 버그다. 지난 2014년 4월 발견됐다. 리눅스를 포함해 오픈SSL에 의존하는 기술이 많아 당시 심각한 보안 문제로 대두됐다. 하트블리드 버그를 패치한 오픈SSL이 곧 나왔지만, 이를 적용하지 않고 있는 서버가 여전히 많다.
[☞관련기사: 그런데요, 하트블리드가 대체 뭔가요?]
[☞관련기사: "한국, 세계 2위 하트블리드 취약점 보유국"]
클라우드플레어 측의 클라우드블리드 패치는 비교적 신속하게 이뤄졌지만, 이 버그로 어떤 사이트의 정보가 얼마나 오랫동안 인터넷에 노출돼 있었는지 가늠하긴 쉽지 않았다. 인터넷을 쓰는 불특정 다수 모두 잠재적 피해자였다. 회사측은 이 문제를 파악하기 위해 후속 조사를 진행했다. 그리고 지난 1일 공식블로그를 통해 잠정 결론을 발표했다.

매튜 프린스 클라우드플레어 공동창립자 겸 최고경영자(CEO) 명의로 게재된 발표 내용에 따르면, 클라우드블리드 버그에 따른 인터넷 사용자의 피해는 당초 우려만큼 광범위하진 않았다. 회사 CDN서비스에 버그가 발생하고 동작한 기간은 지난해 9월 22일부터 제보를 받고 패치를 적용한 지난달 18일까지였다. 약 150일(4개월25일)간 네트워크에서 돌아가는 애플리케이션의 장애 관련 로그를 분석한 결과였다.
[☞원문: Quantifying the Impact of "Cloudbleed"]
프린스 CEO는 "우리는 지난 12일간 우리 네트워크의 실제 요청에 기반한 로그 데이터를 사용해 (버그의) 영향을 더 잘 파악했고, 이로써 고객에게 갈 위험을 예측했다"며 "(초기 발견 사항을 요약하면) 패치되기 전의 버그를 익스플로잇으로 악용한 흔적은 없고, 고객사 대다수는 데이터 유출을 겪지 않았고, 검색엔진 캐시 수만페이지를 검토한 결과 유출된 정보에 우리의 내부 헤더와 고객사 쿠키는 있었지만 (일반인의) 비밀번호, 신용카드번호, 의료기록은 없었다"고 밝혔다.
그는 "클라우드플레어의 미션은 더 나은 인터넷 만들기를 돕는 것"이라며 "우리는 여러분을 실망시켰음을 알고 있으며 사과한다"고 덧붙였다.
■당신이 클라우드플레어 쓰고 있다면
버그가 존재했던 기간 중 서비스에 들어온 요청 가운데 버그를 작동시킨 요청이 124만2천71건이었다. 반 이상은 검색엔진 데이터수집기(크롤러)에서 온 것으로 추정됐다. 클라우드플레어는 구글, MS빙, 야후, 바이두, 얀덱스, 덕덕고 및 기타 검색 사업자와 캐시 소거 작업을 진행했다. 다른 온라인 아카이브 사이트에 올라간 캐시 데이터도 제거했다. 제거된 데이터는 8만페이지 이상 규모였다.

여전히 어딘가에 유출된 데이터가 남아 있을 수 있는데, 이는 고객사 제보를 받아 없애겠다고 회사측은 설명했다.
클라우드플레어 사용자 가운데 실제로 자기가 운영하는 사이트의 정보가 유출돼 검색 캐시에 남아 있을 확률은 얼마나 될까. 이걸 알면 사용자가 클라우드블리드 버그에 따른 위험성을 확률적으로 판단할 수 있을 것이다.
프린스 CEO는 이를 위한 판단 기준을 제시했다.
그는 "타사 캐시에서 데이터가 발견된 고객 150명이 확인한 점에 비춰보면, 일반적으로 고객이 클라우드플레어에 요청을 많이 보낼수록 그 데이터가 메모리에 저장돼 노출될 확률도 올라간다"면서 "네트워크를 통한 월간 요청 건수 기반으로 특정 고객에 대한 데이터 유출 확률을 추정할 수 있다"고 설명했다.
관련기사
- "한국, 세계 2위 하트블리드 취약점 보유국"2017.03.10
- 하트블리드 오명 쓴 '오픈SSL', 새 버전 뜬다2017.03.10
- 오픈SSL 진영, 하트블리드급 새 취약점 해결2017.03.10
- 18년된 SSL3.0 웹 암호화 기술서 취약점 발견2017.03.10
프린스 CEO가 언급한 클라우드플레어 고객수는 600만 곳 이상이다. 그중 서비스에 월간 전송 요청 건수가 1천만건 미만인 고객이 99% 이상이다. 이 경우 버그로 인한 데이터 유출 발생 빈도를 계산하면 확률적으로 1건 미만이 된다. 그는 "세계 규모 100위 웹사이트의 월간 요청 건수가 100억건 미만일 것"이라고도 언급했다.
클라우드플레어 측은 월간 요청건수가 1천만건 이상 100억건 미만인 고객사가 얼마나 되는지 밝히진 않았다. 여기에 해당하는 고객사는 확률적으로 데이터 유출 발생 빈도가 1건에서 1만1천427건까지다. 고객사는 직접 클라우드플레어 애널리틱스 대시보드에 접속해 자기 사이트에서 발생하는 월간 요청 건수를 확인할 수 있다.





