전세계적인 헤드헌팅 서비스의 대세로 자리잡은 링크드인. 구직자에겐 관심있어할 만한 채용공고를 보여주고, 구인중인 기업회원에겐 적당한 구직자를 추천해준다. 타 소셜네트워크서비스(SNS)보다 다양한 추천서비스를 운영하는 링크드인은 빅데이터 플랫폼을 통해 꽤 높은 만족도를 얻어 유명세를 탔다.
지난 15일 열린 네이버 데뷰 2013 두번째날 링크드인에서 소프트웨어엔지니어이자 데이터사이언트시트로 근무하는 김형진씨가 ‘링크드인의 Big Data Recommendation Products – 어제의 데이터를 통해 내일을 예측한다’라는 주제로 발표했다.
김형진씨는 “추천이란 예언이 아니라 예측을 하는 것”이라며 “링크드인은 이런 예측을 위해 머신러닝 알고리즘을 사용하고, 하둡, 키밸류스토어, 기타 오픈소스 등을 사용한 빅데이터에코시스템이란 걸 사용한다”라고 말했다.
링크드인은 2억3천800만명 이상의 가입자를 확보한 대형 SNS다. 링크드인 빅데이터에코시스템은 가입자의 이력서와 인맥 등의 데이터를 통해 적절한 정보를 추천하는 서비스를 제공하는 기반을 이룬다.
김형진씨는 “링크드인의 데이터는 이력서기 때문에, 가입자가 최선을 다해 입력한 솔직하고 고급인 데이터다”라며 “이런 데이터를 바탕으로 다양한 추천제품이 활용된다”고 설명했다.
링크드인의 추천제품은 크게 네가지다. 친구추천, 스킬앤드인도어스먼트, 추천채용공고, 뉴스추천 등이다.
이중 스킬앤드인도어스먼트는 구인자가 누구의 어떤 기술을 승인할 것인가에 대한 제품이다. 김형진씨는 이 제품이 앞서 빅데이터에코시스템 전체를 활용한 예라며 그에 대한 설명을 이어갔다.

빅데이터에코시스템은 추천제품과 사용자가 상호정보를 주고받으면 그 데이터가 하둡 클러스터에 쌓이고, 머신러닝 알고리즘을 돌려 키밸류스토어에 결과를 넣어, 다시 추천제품에 반영하는 구조를 갖고 있다. 분석 모델링 레이어는 인프라 레이어와 분리된 형태다.
배치 프로세싱에 강점을 보이는 하둡을 사용하는 만큼 온라인과 오프라인의 장점을 적절히 조합하는 형태를 지향했다. 오프라인에 가까운 온라인이란 설명이다. 필터링, 최종 비즈니스 로직 적용은 리얼타임, 대규모 머신러닝과 데이터 제너레이션은 오프라인으로 이뤄진다.
링크드인 추천 알고리즘은 과거의 데이터를 통해 모델을 트레이닝하는 과정을 거친다. 일단 사용자의 행동을 관찰하면서, 각 행동에 대해 0점이나 1점으로 스코어를 매긴다. 이렇게 데이터가 쌓이면 모델을 트레이닝하면서 과거 데이터의 오류를 최소화해 최종 모델을 만들어낸다. 이후 미래 조건부 확률 P를 계산해 가입자의 미래 반응을 예측하게 된다.
데이터 제너레이션을 담당하는 하둡 인프라의 경우 매우 복잡한 과정을 거치게 된다. 각 작업의 워크플로우가 수백, 수천개에 이를 정도로 복잡해, 그 중 하나만 잘못되도 전체 추천시스템이 중단될 수 있다. 이를 관리하는 워크플로우 관리툴인 링크드인의 아즈카반은 이런 이유로 고안됐다.
김형진씨는 이후 흥미로운 연구사례 몇가지를 소개했다. 링크드인의 이력서 속에서 뽑아낸 데이터를 바탕으로, 미국 동부와 서부 지역 가입자의 스킬을 살펴봤다. 그러자 실리콘밸리와 유명 IT업체가 위치한 서부 지역에선 최신 IT기술이, 동부에선 마케팅 관련 기술이 많았다.
관련기사
- 하둡2.0 마침내 완성 '운영체제 등장'2013.10.17
- SK텔레콤 오픈소스SW 투자의 의미2013.10.17
- 10주년 ‘링크드인’ 가입자수 2억2천500만명2013.10.17
- “美취업전선, 페이스북-링크드인이 이력서”2013.10.17
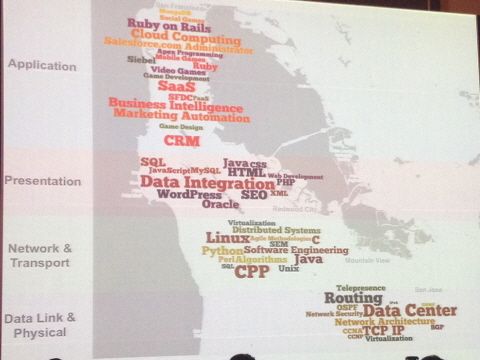
또 한가지 재밌는 사례는 캘리포니아주 샌프란시스코시부터 레드우드시, 마운틴뷰, 산호세에서 근무하는 가입자들의 스킬이다. 캘리포니아주 북쪽으로 갈수록 최신 애플리케이션이나 서비스와 관련된 용어가 나타나며, 남쪽엔 라우팅, TCP/IP, 데이터센터, 클라우드 같은 인프라 관련 용어가 많이 나타났다.
김형진씨는 “내 매니저는 캘리포니아 북쪽으로 갈수록 쿨한 회사라면서, 회사들의 지리적 위치가 마치 네트워크의 OSI 7 레이어같다고 말한 적이 있다”라며 “나중에 데이터를 따져서 보니, 실제로 그렇더라”라고 말했다.