





화성에서 온 개발자와 목성에서 온 데이터베이스 관리자간의 이질적인 개념적 차이를 극복하고자 나온 것이 바로 ORM(Object-Relational Mapping)이다. 기존의 닷넷 개발환경에서는 이러한 ORM 작업이 어려운 작업이었지만 내년 초에 출시될 비주얼스튜디오 2008에 탑재될 LINQ to SQL 디자이너를 통하면 쉽게 구현할 수 있다. 또한 향후 별도로 출시되는 보다 진보된 ADO.NET Entity Framework에 대해서도 같이 소개한다.
애플리케이션을 개발하는데 있어 프로그래밍 언어는 점점 현실의 세계를 그대로 디자인 할 수 있도록 발전해 오고 있다. 이러한 대부분의 애플리케이션에 있어 자료를 저장하려면 데이터베이스는 필수이다. 그런데 자료 저장이라는 것이 물리적인 한계가 있는 작은 모터로 돌아가는 하드 디스크에 저장을 하다 보니 데이터를 표현하는데 있어 물리적인 한계를 고려해야만 한다.
어떻게 하면 보다 적은 공간에 신뢰성 있는 데이터를 저장하고 빠른 속도로 읽어 낼 수 있을까? 이는 데이터베이스를 설계하는 핵심적인 개념이다. 그래서 지금까지도 데이터를 관계형 테이블 형태로 표현을 한다. 현실 세계의 데이터를 관계형 테이블 형태로 나누어서 저장을 해야만 하는데 이를 정규화 한다고 한다.
결국 현실 세계의 추상화된 객체는 관계형 테이블 형태의 데이터로 나누어져서 저장이 되는 것이다. 여기에서 개발자들은 괴리를 느끼게 된다. 애써서 객체 지향 개념으로 클래스를 만들었지만, 정작 DB에 저장을 할 때에는 이를 다시 분해해서 테이블 형태로 저장을 해야만 하는 것이다.
저장뿐만이 아니라, 조회하는데 있어서도 여러 테이블에 흩어져 있는 데이터를 다 모아서 조회를 해야만 한다. 이렇게 서로 다른 두 도메인 간의 개념적 차이를 이해하고 개발하려면 개발자가 DB의 테이블 구조도 잘 알아야만 한다. 따라서 이러한 부분이 개발의 생산성을 낮추는 주범으로 지목되기 시작했다.
이러한 두 도메인 간의 이질적인 환경을 통합해 주는 것을 ORM(Object-Relational Mapping)이라고 한다. ORM은 오픈 소스나 자바 진영에서는 많은 관심을 끌고 있지만 Microsoft(이하 MS) 진영에서는 별 다른 주목을 받지 못했다. 그러나 내년에 출시 될 비주얼스튜디오 2008에 LINQ라는 개념이 도입되면서 앞으로 많은 관심을 끌 것으로 보인다.
LINQ는 Language Integrated Query의 약자로 쿼리 구분을 언어 속에 포함 시킨 개념이다. 이러한 시도는 먼저 영국에 있는 MS 캠브리지 연구소에서 Cw라는 언어를 만들면서 쿼리 구문을 언어 속에 포함 시키는 연구를 해오다가 이번 비주얼스튜디오 2008에 탑재될 C# 3.0에 이 개념을 포함시켰다.
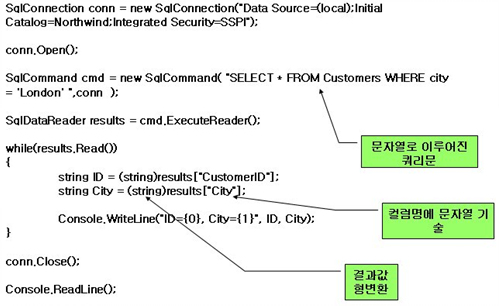
기존의 데이터베이스 쿼리 구문을 보면 <그림1>과 같다.
<그림 1>을 보면 쿼리 구문이 문자열로 만들어져 있고, 컬럼명을 문자열로 표현하고 있으며, 결과 값의 형 변환도 하고 있다. 이러한 일련의 활동은 컴파일 타임에 오류 체크를 못하므로 결국 잠재적인 오류를 만들어 낼 가능성을 가지고 있다. 이를 언어 속에 포함 시키면 <리스트 1>과 같이 된다.


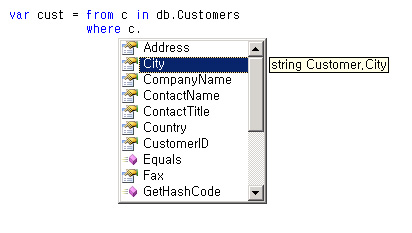
쿼리 구문을 문자열로 만들지 않았으므로 컴파일 타임에 오류를 체크할 수 있다. 또한 인텔리센스 기능도 지원하는데 <화면 1>을 보면 City 속성이 자동으로 나오는 것을 볼 수 있을 것이다.

<그림 1>의 쿼리 구문을 보면 일반적인 SQL 구문과 비슷한 구조인 것 같은데 FROM 절이 먼저 나왔다. 그 이유는 인텔리센스를 지원하기 위해서 FROM 절을 앞으로 뺀 것이다.
이러한 독립적인 쿼리 구문을 데이터베이스에 적용 시킨 것을 LINQ to SQL이라 부른다. 데이터베이스뿐만 아니라 XML (LINQ to XML)와 DataSet(LINQ to DataSets) 같은 다른 객체들에게도 적용이 가능하다.
LINQ 기술에서 쿼리 구문이 언어로 들어오려면 먼저 관계형 데이터를 객체로 변환해 주어야만 언어에서 연산을 수행할 수 있다. 기존에도 관계형 데이터에 대해 Typed DataSet이라고 하여 객체로 표현하는 방법이 있었지만 그리 편하게 만들 수 있는 것이 아니어서 많이 사용되지는 못했다.
하지만 이번에는 LINQ to SQL Designer를 이용하면 보다 편하게 관계형 데이터를 객체로 변환할 수 있다.

2007년 7월에 비주얼스튜디오 2008 베타2 버전이 나왔는데(http://msdn2.microsoft.com/en-us/vstudio/aa700831.aspx) 이를 기준으로 간단한 애플리케이션을 만들면서 설명 할 것이다.
부서와 사원이 있는 간단한 테이블을 만들어 보자. 한 부서에는 여러 명의 사원이 있을 수 있으므로 이들 사이의 관계는 일대다 관계가 된다. 일반 프로젝트에서 LINQ to SQL Classes라는 아이템을 추가하면 바로 ORM Designer가 나타난다. 여기에 해당 테이블을 끌어다 놓기만 하면 자동으로 관계를 맺어준다.
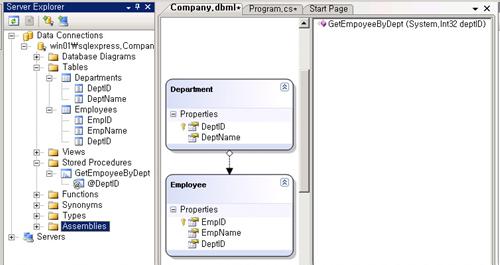
<화면 2>를 보면 DB에서 해당 테이블을 끌어다 놓으면 자동으로 만들어진 다이어그램과 관계를 볼 수 있다. 또한 저장 프로시저나 뷰도 지원하므로 필요하면 끌어다 놓으면 자동으로 인식한다. 여기에서는 부서 ID로 사원을 검색할 수 있는 저장 프로시저 한 개를 끌어다 놓았다. 이때 저장 프로시저의 리턴 타입에는 Employee를 지정한다(참고로 자세히 보면 테이블명은 복수 명사로 되어 있는데, 클래스명은 단수 명사로 바뀌어 있는 것을 볼 수 있을 것이다.
이는 닷넷 클래스 이름 관례에 따라 복수 명사의 경우 자동으로 단수 명사로 바꾸어 준다). 이렇게 디자인하여 저장 하면 자동으로 클래스를 만들어 준다. 각각의 테이블은 엔티티(Entity)라고 부르는 클래스로 만들어지며, 이들 엔티티와 외부에서 엔티티에 접근하는 저장 프로시저를 모두 포괄하는 객체인 데이터 콘텍스트(DataContext)도 만들어 준다. 만들어진 엔티티 클래스를 보면 베이스 클래스가 없는 것을 볼 수 있을 것이다.
따라서 부모 클래스가 필요하다면 엔티티 클래스에 부모 클래스를 지정해서 기능을 확장 할 수 있다. 또한 Partial 클래스로 지정되어 있으므로 외부에서 마음대로 클래스를 확장하거나 수정할 수도 있다. 이제 이 데이터 콘텍스트를 이용해서 DB에 접근을 하고 각각의 엔티티를 통해서 작업을 하면 된다. 몇 가지 예제를 보자.
저장 프로시저 사용하기
저장 프로시저를 이용해서 1번 부서의 사람들을 조회하려면 <리스트 2>와 같이 하면 된다.
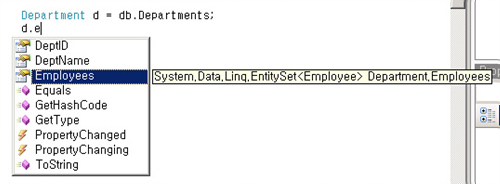
저장 프로시저는 강력한 타입(strongly-typed)으로 정의되어 있기 때문에 별도의 타입 변환 없이 사용할 수 있다. <리스트 2>를 보면 한 가지 재미있는 속성이 있는데, Employee 클래스의 Department 속성이다. 이는 부서와 사원이 1:N의 관계에 있으므로 한 부서에는 여러 명의 사원이 있을 수 있다.
따라서 사원의 입장에서는 자신이 한 부서에만 속할 수 있으므로 사원 클래스에는 부서 정보가 하나의 속성으로 있는 것이고 부서 입장에서는 여러 명의 사원을 둘 수 있으므로 사원 클래스가 콜렉션(collec tion) 속성으로 있게 된다.
즉, 현실 세계에서는 이러한 관계가 가능하지만 DB에서는 이러한 관계 정보를 직관적으로 표현하지 않는다. DB에서는 사원 테이블에 부서 테이블의 키가 외래키로 등록이 되어서 사원 테이블에서 부서 테이블의 키만 알 수 있다. 부서 이름까지 알려면 JOIN을 통해서 확인야만 한다.
하지만 예에서 보듯이 클래스로 만들게 되면 부서 클래스의 인스턴스를 가리킬 수 있으므로 직관적으로 부서명을 얻어 올 수 있다.
한편 DB의 부서 테이블만 보면 어떤 사원이 연결되어 있는지 전혀 정보가 없다. 하지만 위의 클래스에서는 부서 테이블에 사원 클래스가 집합 형태로 연결되어 있으므로 손쉽게 접근이 가능하다. ORM은 이러한 두 도메인의 개념적인 차이를 연결시켜주는 중재자 역할을 하고 있는 것이다.
업데이트 작업
이번에는 업데이트 작업을 해보자.
LINQ TO SQL에서는 삽입/삭제/갱신등과 같은 작업을 하는 SQL 구문을 자동으로 만들어 준다. 따라서 <리스트 3>과 같이 그냥 객체의 속성을 수정하고 마지막에 SubmitChanges()라는 메소드를 호출하면 이전까지의 모든 작업을 저장하는 SQL 구문을 자동으로 만들어서 수행한다.
특히 업데이트의 경우에는 기본적으로 낙관적 동시성 제어를 한다. <리스트 4>는 프로필러에서 캡처한 내용이다.
SQL 구문을 보면 과거에 부서 코드가 1인 값을 찾아서 2로 바꾸는 것을 볼 수 있을 것이다. 즉, 누군가 동시에 이러한 작업을 하는 경우 부서 코드가 변경되기 이전 값도 비교함으로써 동시성 문제를 해결하고 있다.
이러한 삽입/삭제/갱신 구문을 사용자가 별도의 로직을 넣어서 임의대로 수정하여 사용해야 할 경우도 있을 것이다. 그럴 때에는 별도의 저장 프로시저 구문을 만들어서 연결해 주면 된다.
서버 사이드 페이징
아마 웹 애플리케이션을 만들 때 게시판의 페이징은 기본적으로 사용할 것이다. 그런데 이 페이징을 구현하는 것이 쉽지 않아서 여간 번거로운 것이 아니다. LINQ to SQL에서는 클라이언트의 부하를 줄여주는 서버 사이드 페이징 기능이 추가 되었다. 다음은 페이징의 예제다.
var employees = (from e in db.Employees
select e).Skip(5).Take(5);
이 구문은 한 페이지가 5개라는 가정 하에 2페이지를 표시하기 위해서 5개를 건너뛰고 5개를 표시하라는 명령어이다. 수행 결과를 보면 다음과 같다.
<리스트 5>를 보면 먼저 전체 내용을 다 보인 후에 2페이지를 출력한 결과를 보여 주고 있다. 5개를 건너뛰었으므로 6부터 나오며, 5개만 보여 주라고 하였기 때문에 10까지 나왔다. 그렇다면 정말 서버 사이드 구문이 실행이 되었는지 확인해 보자.
비주얼스튜디오 2008 베타2 부터는 실제 변환된 쿼리 구문을 디버깅을 통해서 쉽게 확인이 가능하다. 쿼리 문장에 브레이크 포인트를 설정하고 나서 마우스를 올려놓으면 해당 쿼리 구문이 보인다.
<화면 4>의 내용을 자세히 보면 <리스트 6>과 같다.
파라미터까지 포함하여 프로필러에서 잡은 구문은 <리스트 7>과 같다.
<리스트 7>을 보면 전체 데이터에 대해서 넘버링을 한 다음에 SKIP 구문에 해당하는 수 보다 큰 데이터를 가져와서 TAKE 구문에 있는 숫자만큼 TOP으로 걸러서 가져오고 있다.
트랜잭션
LINQ TO SQL에서는 SubmitChanges()호출하기 이전까지의 모든 작업을 트랜잭션으로 묶어서 작동을 한다. 따라서 별도의 트랜잭션을 걸지 않아도 자동으로 트랜잭션 처리가 된다. <리스트 8>의 예제를 보자.
<리스트 8>을 보면 두 번의 업데이트 작업을 하고 있다. 이들이 정말 모두 트랜잭션으로 묶여서 처리가 될까? 프로필러로 확인해 보자.
<화면 5>를 보면 두 개의 업데이트 구문을 하기 전에 앞뒤로 트랜잭션 처리 구문이 들어가 있는 것을 확인 할 수 있다. 이러한 암묵적인 트랜잭션 이외에도 .NET Framework 2.0에 있는 TransactionScope 객체를 이용해서 명시적으로 트랜잭션을 걸 수도 있다.
이 기능은 데이터베이스뿐만 아니라, MSMQ나 파일 시스템(Windows Server 2008에서는 파일 시스템이 트랜잭션 기능을 지원한다) 등과 같이 데이터베이스가 아닌 다른 시스템과의 트랜잭션 처리도 가능하다.
LINQ TO SQL의 ORM 구조는 관계형 데이터를 바로 객체에 매핑을 하고 있다. 그래서 바로 C #이나 VB 형태의 클래스로 매핑을 한다. 이러한 방법의 장점은 만약 DB 컬럼명이 변경되더라도 비즈니스 로직단의 프로그램은 수정하지 않고 매핑 클래스만 수정해 주면 된다는 점이다. 즉 DB와 객체가 서로 분리되어 매핑을 하므로 서로 독립적인 관계를 맺을 수 있는 것이다.
한 예로 Departments 테이블의 부서명 컬럼인 DeptName 컬럼명이 DeptTitle로 변경되었다고 하자. <리스트 9>는 기존 프로그램이다.
이 프로그램의 소스는 수정하지 않고 매핑해 주는 클래스 정보만 수정해 보자. <리스트 10>을 보면 DB 테이블에 매핑하는 속성인 Column의 Name 값을 DeptTitle로 바꾼 것을 볼 수 있을 것이다.
이렇게 수정하기만 하면 비즈니스 로직을 고치지 않고서도 원하는 결과를 얻을 수 있다. 그런데 이러한 수정을 하고 나서 다시 컴파일을 해야만 반영이 된다. 즉, 데이터베이스와 객체가 서로 완벽하게 독립적이지 않고 묶여있다는 것이다.
이러한 문제점을 해결하고자 제시한 개념이 ADO.NET Enti ty Framework이다. 아직은 베타 버전인데, 내년 초 비주얼스튜디오 2008이 출시된 이후에 따로 애드인으로 추가 될 예정이다. 엔티티 프레임워크의 가장 큰 특징은 바로 계층적 아키텍처 구조라고 할 수 있다.
기존 LINQ to SQL에서는 데이터베이스와 객체가 서로 밀접한 관계에 있었다면 엔티티 프레임워크에서는 이들을 3계층(Layer)으로 나누어서 서로 독립적인 환경을 보장하고 있다.
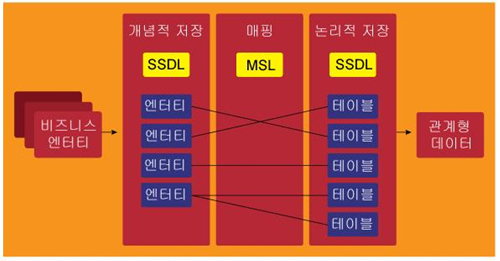
첫 번째로 개발자의 입장에서 바라보고 있는 개념적 계층(Conceptual Layer)이다. 개발자는 객체 지향적인 관점에서 현실 세계를 객체 단위로 인식을 하기 때문에 이를 개념적 계층으로 표현한다.
두 번째는 논리적 계층(Logical Layer)이다. 논리적 계층은 데이터베이스 입장에서 관계형 테이블 형태로 현실 세계의 객체를 쪼개서 표현하는 개념이다. 마지막 계층은 매핑 계층(Mapping Layer)으로 개념적 계층과 논리적 계층 사이에서 둘을 연결 시켜주는 계층이다. 이렇게 세 개의 계층을 정의하는데 있어 유연한 XML 형태의 데이터로 표현한다.
따라서 환경의 변화에 쉽게 대응할 수 있다. 각각의 계층을 표현하는 XML 표현식에 별도의 명칭을 붙이고 있다. 개념적 계층에는 CSDL(Co nceptual Schema Definition Language), 논리적 계층에는 SSDL(Store Schema Definition Language), 매핑 계층에는 MSL(Mapping Schema Language)라는 이름을 붙이고 있다 (<화면 6> 참조).
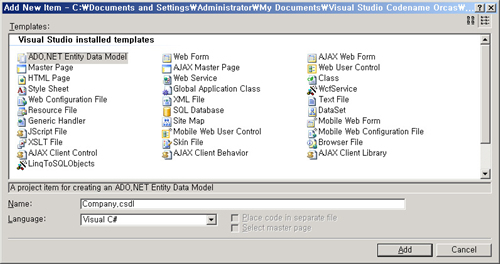
한 예로 앞서 만들었던 예제와 동일한 예제를 ADO.NET Entity Data Model로 만들어 보자. <화면 7>은 Entity Data Model을 추가하는 화면이다.
ADO.NET Entity Data Model을 추가하면 마법사가 동작하면서 원하는 테이블을 선택하면 <화면 8>처럼 자동으로 3개의 계층이 만들어 진다.
여기에서도 앞의 예제와 같이 부서 테이블의 부서명 컬럼이 DeptName에서 DeptTitle로 바뀌었다면, 단순히 2개 계층의 XML 데이터만 수정해 주면 된다. 먼저 논리 계층의 SSDL을 <리스트 11>과 같이 수정한다.
데이터베이스 정보를 정의하는 부분이므로 컬럼명을 실제 데이터베이스에 있는 컬럼명으로 수정을 한 것이다. 다음에는 매핑 정보인 MSL을 <리스트 12>와 같이 수정한다.
DeptName을 DeptTitle 컬럼에 매핑 시키는 부분을 수정하는 것이다. 이렇게만 하면 기존 프로그램의 소스는 수정하지 않고도 변경할 수 있다. 해당 프로그램은 <리스트 13>과 같다.
<리스트 13>에서 쿼리 구문으로 LINQ 구문을 사용하였는데 이번에는 대상이 엔티티 프레임워크이므로 이를 LINQ to Entities라고 한다. 결과는 수정 전후 동일하게 나온다.
엔티티 프레임워크의 가장 큰 특징인 계층적 분리로 인하여 서로 다른 독립적인 데이터베이스에 대해서도 매핑이 가능하다. 한 테이블은 MS SQL Server에 존재하고 다른 테이블은 오라클 데이터베이스에 있더라도 하나의 엔티티로 묶을 수 있다.
또한 데이터베이스 변경이 쉬우므로 애플리케이션을 MS SQL Server 용으로 제작 하였다가도 소스 코드의 변경 없이 오라클 데이터베이스로 매핑 정보만 변경하면 쉽게 다른 DB로 바꿀 수 있다.
그렇다면 언제 LINQ to SQL을 사용하고 엔티티 프레임워크를 사용해야 할까? 이 문제에 대해 MS의 데이터 프로그래밍 아키텍트인 Mike Pizzo가 자신의 블로그에서 언급을 하였는데 요약을 하면 다음과 같다.
● LINQ to SQL은 MS SQL Server를 기반으로 하는 신속한 개발(Rapid Development) 환경에 적합하고 엔티티 프레임워크는 MS SQL Server와 다른 데이터베이스를 대상으로 느슨한 연결(loosely coupled)과 유연한 매핑(flexible mapping)을 해야 하는 경우에 적합니다.
● LINQ to SQL은 신속한 개발(Rapid Development)에 초점이 맞추어져 있으며, 엔티티 프레임워크는 대규모 엔터프라이즈급 환경에 적합하다.
아직 ADO.NET Entity Framework은 베타 버전이고 앞으로 어떻게 변할지 모른다. 그리고 LINQ to SQL과는 어떤 차별화 된 기능으로 다른 길을 걸어갈지 아직은 모른다. 내년 초에 어떤 모습으로 나타날지 기대가 된다. @
참고자료
1. LINQ 프로젝트 사이트: http://msdn.microsoft.com/netframework/future/linq
2. ADO.NET 팀 블로그: http://blogs.msdn.com/adonet/default.aspx
3. ADO.NET Entity Framework 샘플: http://www.codeplex.com/adonetsamples
4. MSDN 2007년 7월호, ADO.NET Entity Framework Overview
5. ADO.NET Orcas 포럼: http://blogs.msdn.com/adonet/default.aspx
6. ScottGu의 블로그: http://weblogs.asp.net/scottgu
* 이 기사는 ZDNet Korea의 제휴매체인 마이크로소프트웨어에 게재된 내용입니다.

지금 뜨는 기사
이시각 헤드라인




ZDNet Power Center
