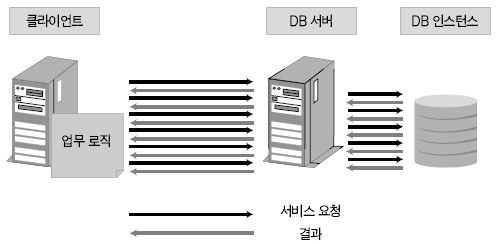
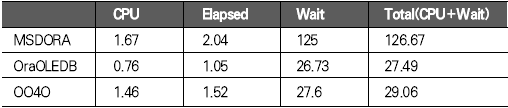
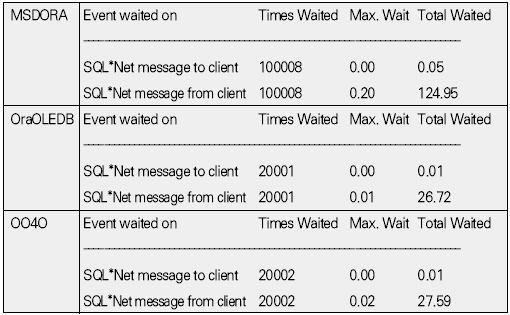
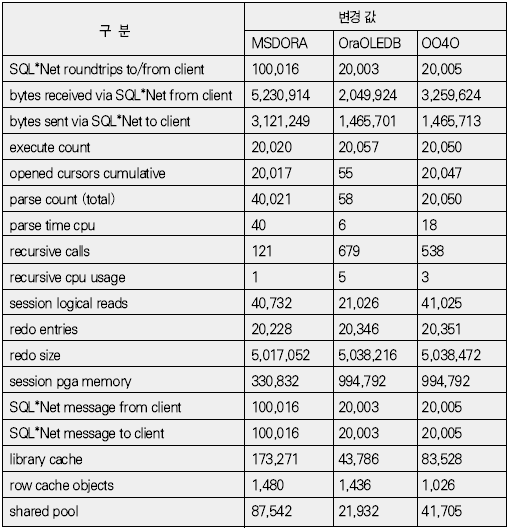
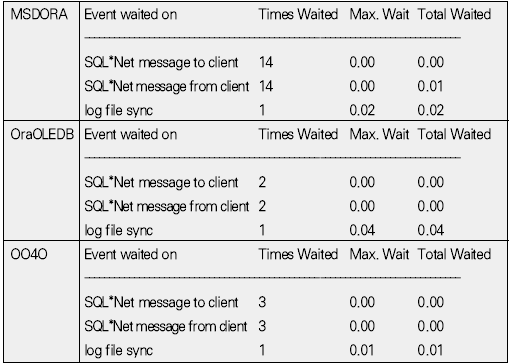
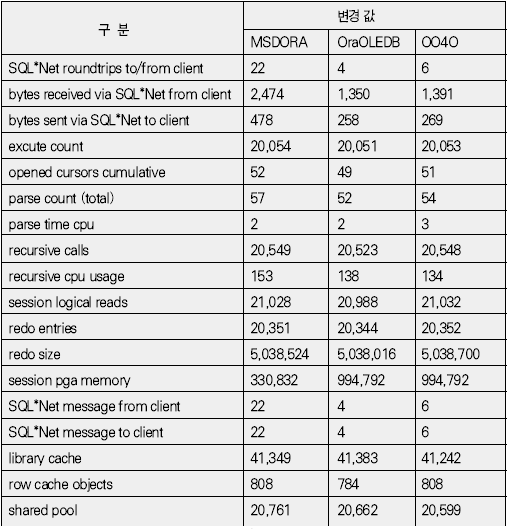
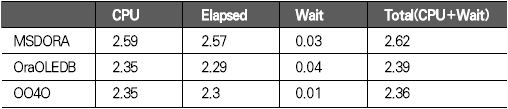
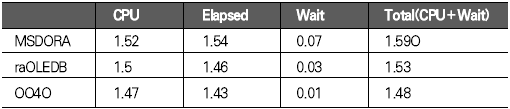
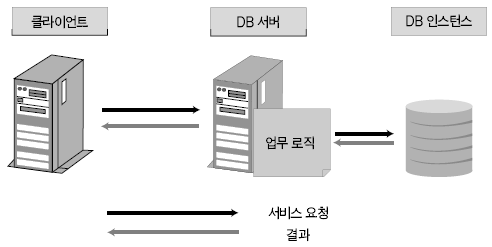
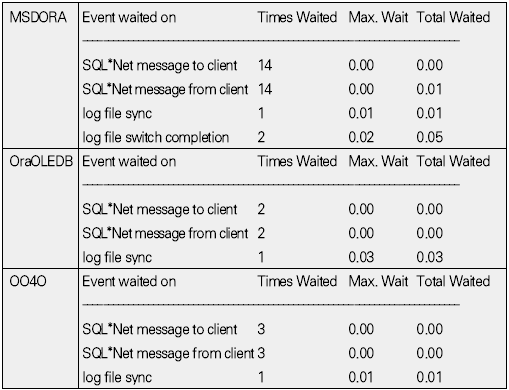
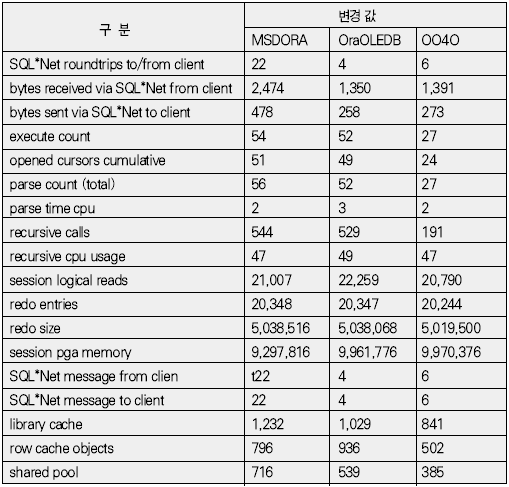
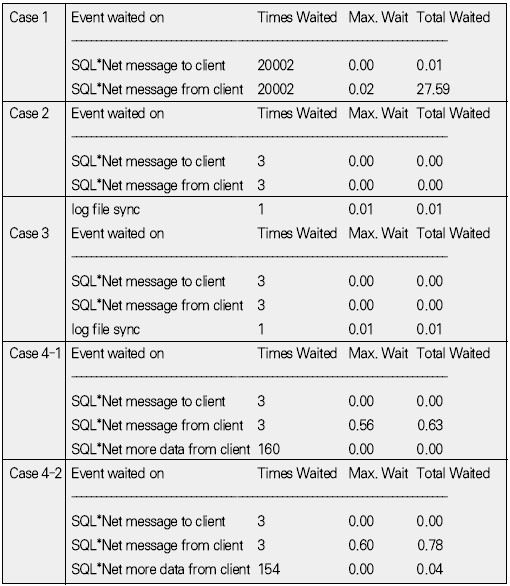
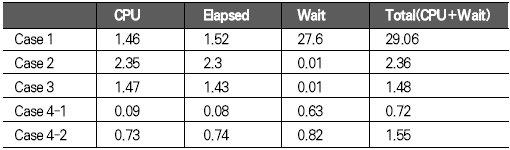
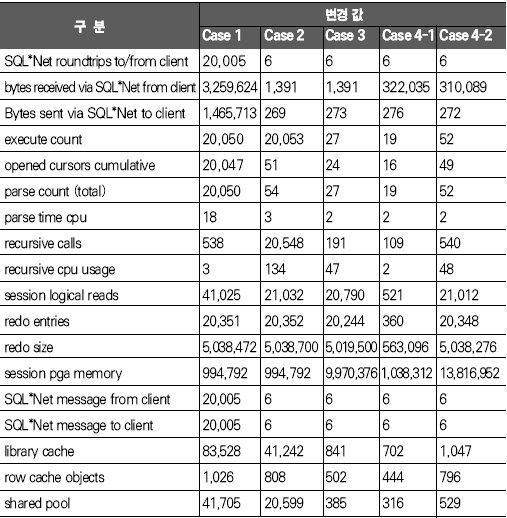
운영체제 개발도구 기초지식 응용분야 ADO는 OLE(Object Linking and Embedding) DB를 이용해 관계형 데이터베이스뿐만 아니라 파일과 같은 비관계형 데이터 소스에 접근할 수 있다. OLE DB는 프로바이더(provider)라는 컴포넌트를 통해 데이터 소스로부터 자료를 제공하는 역할을 수행하는데 소스별로 서로 다른 프로바이더가 사용된다. 지난 연재에서는 MS의 DAC로 ADO를 사용했으며 프로바이더로는 오라클의 OraOLEDB(Oracle Provider for OLE DB)를 사용했다. 이번에는 MSDORA(Microsoft Oracle ODBC Driver and OLEDB) 프로바이더도 함께 사용해 동일한 환경, 동일한 수행방식에서 프로바이더가 다른 경우의 성능이 어떻게 차이가 나는지를 살펴본다. 프로바이더의 제공자가 MS든 오라클이든 모두 ADO의 일종이므로 자료 처리를 위한 소스는 동일하게 사용할 수 있다. 반면 오라클에서는 윈도우 개발환경에서 사용할 수 있는 별도의 DAC, 즉 OO4O를 제공하는데 문법도 ADO와 다소 차이가 있다. 따라서 ADO를 사용하면 프로바이더가 변경되더라도 프로그램 자체에 영향이 없지만, ADO를 사용하다가 OO4O로 변경하거나 그 반대의 경우에는 데이터베이스 액세스를 담당하는 부분을 알맞게 수정해야 한다. OO4O는 ADO와는 달리 오라클 데이터베이스만을 위해 개발됐기 때문에 ADO보다 더 많은 기능을 지원하며 오라클에서 더 좋은 성능을 내는 것으로 알려져 있다. 이에 대해서는 실제 테스트를 통해 ADO를 사용하는 경우와 OO4O를 사용하는 경우 어떤 성능 차이를 보여주는지 살펴볼 것이다. 테스트 환경과 방법 이번 테스트는 다음과 같은 환경에서 수행했다. DB 서버 CPU : 1.7Hz × 8EA 메모리 : 16GB 오라클 서버 : 오라클 9i 엔터프라이즈 에디션 릴리즈 9.2.0.4.0 64비트 운영체제 : AIX 5.2 64비트 클라이언트 CPU : 인텔 펜티엄 M 1.5GHz × 1EA 메모리 : 1GB 오라클 클라이언트 : 오라클 10g 10.1.0.2 운영체제 : 윈도우 XP 프로페셔널 테스트는 2만 건의 자료를 테이블에 Insert하는 작업으로 테스트를 위해 Number Type을 갖는 2개의 컬럼과 Varchar2 Type을 갖는 1개의 컬럼에 정해진 규칙으로 2만 건을 입력하는 방식으로 수행했다. 사용되는 DAC 별로 각각 <케이스 1>부터 <케이스 3>까지는 지난 호와 동일한 방식으로 테스트했으며 OO4O를 사용한 <케이스 4>가 추가됐다. <케이스 1> 클라이언트에서 2만 건의 자료를 데이터베이스로 Loop 방식으로 Insert <케이스 2> 데이터베이스에서 2만 건의 자료를 Loop 방식으로 Insert <케이스 3> 데이터베이스에서 2만 건의 자료를 Array 방식으로 Insert <케이스 4> 클라이언트에서 2만 건의 자료를 생성한 후 데이터베이스에 Array 방식으로 Insert <케이스 4>를 위해 <화면 1>처럼 엑셀 비주얼 베이직 에디터의 도구 메뉴의 참조 화면에서 ‘Oracle InProc Server 5.0 Type Library’를 선택한다. 테스트에 사용된 클라이언트 프로그램과 측정 방식은 모두 동일하므로 여기서는 바로 각 DAC별 테스트 결과를 분석해보자. 케이스 1, 클라이언트에서 DB로 Loop 방식으로 Insert <케이스 1>은 클라이언트에서 자료를 생성해 생성 시점에서 데이터베이스에 작업 요청을 하는 방식으로 이루어진다. 클라이언트에 자료가 반복적으로 생성되면 데이터베이스에 대한 요청도 반복적으로 이루어지고 그를 통해 네트워크 I/O 및 데이터베이스에 대한 수행 요청이 많이 발생하는 구조이다. <케이스 1> 테스트에 필요한 소스는 ‘이달의 디스켓’으로 제공한다. 각각 MSDORA, OraOLEDB, OO4O의 순으로 표시했다. 먼저 <표 1>과 같이 소요시간을 비교해보자. 여기서 CPU 항목은 순수하게 자료 처리에 사용된 시간이며, Elapsed 항목은 CPU 값에 데이터베이스 Wait 값이 추가된 값이다(이 때 데이터베이스 Wait 값은 데이터베이스에서 자료 처리 과정에서 발생하는 Wait로 <표 1>의 Wait 항목과는 다른 것이다). Wait 항목은 Level 8의 트레이스 결과로 출력된 Wait 시간의 합이다. <케이스 1>의 경우 반복되는 네트워크 I/O로 인한 지연시간이 가장 중요한 요소이므로 이 시간을 측정하기 위해 일반적으로 대기시간으로 간주되지 않는 Wait(예를 들면 SQL*Net message from client)가 중요하게 사용됐으며 전체 수행시간은 CPU 항목과 Wait 항목의 합으로 표시했다. 테스트 시작 시점에서 데이터베이스와 연결되고 종료 시점에 연결이 끊어지므로 일반적으로 SQL*Net message from client, 즉 사용자에 의한 유휴시간은 발생하지 않았다. 이제 <표 1>의 결과치를 해석해보자. 동일한 방식으로 수행했음에도 불구하고 사용한 드라이버의 종류에 따라 최고 4.5배의 차이가 나고 있음을 알 수 있다. 순수 처리 시간에서는 약 2배 정도 밖에 차이가 나지 않았지만 SQL*Net message from client라는 Wait 값이 의미있는 Wait 시간으로 간주되면서 전체 수행시간에서 큰 차이를 나타냈다. <화면 2>는 트레이스 파일 내용 중 전체 Wait 항목 부분이다. Times Waited는 Wait 이벤트가 발생한 횟수이며 Max. Wait는 발생된 이벤트 중 최대 대기시간이다. Total Waited는 총 대기시간을 의미한다. <화면 2>를 보면 SQL*Net message to client와 SQL*Net message from client에서만 Wait가 발생한 것을 알 수 있다. SQL*Net message to client는 데이터베이스 서버에서 메시지를 보내는데까지 소요된 시간이며, SQL*Net message from client는 SQL*Net message to client 이후 클라이언트로부터 메시지가 오기까지의 소요시간이다. 여기에는 데이터베이스의 메시지가 네트워크를 통해 클라이언트에 도착하기까지의 소요시간, 클라이언트에서의 처리시간 및 대기시간, 클라이언트의 메시지가 네트워크를 통해 데이터베이스 서버로 도착하는 시간 등이 포함된다. <화면 2>를 보면 SQL*Net message from client에 따른 Wait 시간이 SQL*Net message to client보다 월등히 크게 나타난 것을 알 수 있다. MSDORA의 경우 Times Waited가 OraOLEDB, OO4O에 비해 5배가 많기 때문에 시간도 약 5배 가량 더 많이 소요됐다. 다음으로 <화면 3>과 같이 데이터베이스 내부의 작업 내용을 알아보자. 수행시간 비교를 통해 Wait 값 특히 SQL*Net message from client 값에서 많은 차이를 보였으므로 네트워크 관련 지표를 통해 원인을 찾아보자. <화면 3>의 SQL*Net roundtrips to/from client 지표를 보면 MSDORA가 OraOLEDB, OO4O보다 5배 많은 네트워크 I/O 횟수를 보이고 있음을 확인할 수 있다. 네트워크를 통한 자료 이동량도 2배 가량 높다. 결론적으로 네트워크를 통해 얼마나 많은 자료가 이동했는가 보다는 얼마나 많은 횟수로 이동했는가가 전체 수행시간에 결정적인 영향을 끼쳤음을 알 수 있다. OraOLEDB와 OO4O는 가장 많은 시간을 소요한 네트워크 I/O면에서 거의 비슷해 큰 차이가 없다. 하지만 <화면 3>의 소요시간 비교 항목을 자세히 보면 OraOLEDB가 OO4O보다 조금 더 빠르게 처리됐음을 알 수 있다. 여기엔 몇 가지 이유가 있는데 Parse 횟수, Cur sor Open 횟수에서 OraOLEDB가 더 효율적으로 작업했기 때문이다. Parse 횟수가 적다는 것은 library cache, shared pool 등의 자원을 적게 사용해 실행 시간을 단축하는 효과가 있다. 또한 OraOLEDB, OO4O가 MSDORA보다 recursive calls 지표 측면에서 더 많은 자원을 사용한 것으로 나타났으며 그로 인해 CPU 사용 시간(recursive cpu usage)도 더 많은 것으로 나타났다. 케이스 2, DB에서 Loop 방식으로 Insert <케이스 2>는 테이블에 Insert할 자료를 데이터베이스 서버에서 생성하며, 클라이언트는 데이터베이스 서버의 Stored Procedure를 호출하는 방식으로 실행된다(<그림 2>). 데이터베이스 서버가 업무 로직을 처리하며, 작업이 끝날 때마다 데이터베이스에 작업 수행을 요청하는 방식이다. <케이스 2>에 사용된 소스는 지면 관계상 ‘이달의 디스켓’으로 제공한다. <표 2>를 보면 <케이스 2>는 <케이스 1>과 달리 드라이버간 편차가 크지 않음을 알 수 있다. 클라이언트는 데이터베이스의 프로시저를 호출하고 데이터베이스에서 자료 생성과 테이블에 삽입 작업이 끝난 후 클라이언트에게 그 결과만을 알려주므로 네트워크 자원을 매우 적게 사용하고 이 때문에 서로 간의 시간 차이가 거의 나타나지 않았다. <케이스 1>의 경우 네트워크 관련 지표에서 큰 차이가 있었지만 <케이스 2>처럼 실행방식을 변경하자 이런 차이가 없어졌다. 특이한 것은 log file sync라는 새로운 Wait 이벤트가 1회 나타난 것이다. 이것은 변경된 자료가 로그 버퍼에 반영되는 과정에서 발생한 것으로, <케이스 1>에 비해 훨씬 짧은 시간에 동일한 자료량의 변경이 있었기 때문이다. 그러나 이 부분도 DAC별 차이는 미미한 수준이다. 한편 CPU 처리시간을 보면 MSDORA와 OraOLEDB, OO4O 간에 0.2초 정도의 편차가 존재한다. 소요시간은 시스템 상황에 따라 약간의 편차가 발생하므로 이것만으로 단순하게 우열을 가릴 수 없는 경우가 있으며, <케이스 2>의 경우에도 큰 의미는 없는 것으로 보인다. <화면 5>는 <케이스 2>의 주요 데이터베이스 활동 지표다. SQL* Net roundtrips to/from client를 기준으로 <케이스 1>과 비교하면 네트워크 I/O량이 크게 줄어들었음을 알 수 있다. MSDORA가 OraOLEDB보다 여전히 5배 정도 네크워크 I/O를 더 많이 수행했지만 이 정도 수치가 되면 전혀 영향이 없다고 봐도 무방하다. 내부적으로 사용한 데이터베이스 자원 사용량에서는 동일한 데이터베이스의 프로시저를 사용했기 때문에 거의 차이가 없다. 다만 메모리 사용량에서는 MSDORA가 OraOLEDB, OO4O보다 더 적은 량의 메모리를 사용하는 것으로 나타났다. 이는 <케이스 1>의 경우에도 마찬가지였으나 <케이스 2>는 <케이스 1>보다 전체적으로 자원을 더 적게 사용하면서도 더 빠른 처리시간을 보였다(이 부분은 지난 호에서 자세히 살펴봤다). 케이스 3, DB에서 Array 방식으로 Insert <케이스 3>은 테이블에 Insert할 자료를 데이터베이스 서버에서 생성하고 클라이언트는 데이터베이스 서버의 Stored Procedure를 호출하는 방식이다(<그림 3>). 데이터베이스 서버 부분에서 업무 로직을 처리하고 데이터를 테이블에 Insert한다는 점까지는 <케이스 2>와 동일하지만 <케이스 2>가 업무 로직이 처리될 때마다 데이터베이스에 수행 요청을 하는 반면 <케이스 3>은 처리할 데이터를 각 건 별로 처리하지 않고 Array 방식으로 모아서 처리한다. 즉 업무 로직을 담당하는 TEST_PROC 프로시저를 데이터베이스 서버에 생성한 후 클라이언트에서 데이터베이스 서버의 프로시저를 수행하는 방식이다(관련 스트립트는 ‘이달의 디스켓’으로 제공한다. VBA에서 수행되는 것으로 실제 처리를 담당하는 부분만 기술하였으며 클라이언트 부분은 <케이스 2>와 동일하다). <표 3>을 보면 <케이스 3>도 <케이스 2>처럼 각 프로바이더 별로 의미있는 차이가 발생하지 않았음을 알 수 있다. 클라이언트는 데이터베이스의 프로시저를 호출하고 그 결과를 받는 역할만을 수행하며 실제 자료 생성이나 테이블에 Insert 작업은 데이터베이스에서 발생하므로 차이가 발생할 여지가 없었던 것이다. 다만 MSDORA의 경우 Wait 시간이 다른 프로바이더보다 더 길었다. <화면 6>을 보면 MSDORA의 경우 log file switch completion이라는 Wait Event가 발생해 0.05초의 시간이 소요된 것을 확인할 수 있다. 이것은 데이터베이스가 사용하는 online redo log file이 바뀌는 경우 발생하는데, 변경된 자료가 online redo log file에 누적 기록되면 어느 순간 해당 파일에 변경된 내용이 가득 차고 다음 로그 파일에 기록하기 위해 준비하는 과정에서 나타난다. 데이터베이스 운영 중 발생한 정상적인 Wait 이벤트이므로 여기서는 무시한다. <케이스 3>의 경우 <화면 7>처럼 네트워크 관련 지표에서도 MSDORA가 조금 큰 값을 나타낼 뿐 각 DAC 별로 두드러지는 차이점은 없었다. 케이스 4, 클라이언트에서 자료생성 후 Array 방식으로 Insert <케이스 4>는 이번 호에 새롭게 추가됐다. <케이스 1>과 마찬가지로 자료를 생성하는 부분이 클라이언트에 위치하지만 <케이스 1>이 자료 생성 시마다 Insert를 수행한 반면 <케이스 4>는 클라이언트에서 자료를 모두 생성한 후 Array 방식으로 데이터베이스에 자료를 전송해 단 1회 Insert 작업을 수행한다(<그림 4>). 언듯 보면 <케이스 3>과 동일해 보이지만 <케이스 3>이 단순하게 데이터베이스의 프로시저 수행을 요청했다면 <케이스 4>는 클라이언트에서 자료를 생성해 그 자료 자체를 1회의 요청으로 처리한다. <케이스 4>는 OO4O를 통해 구현되며 구체적인 방식은 따라 다시 두 가지로 나뉜다. 한 가지는 클라이언트 부분에서 완전하게 처리를 마친 후 Array 방식으로 테이블에 Insert를 시키는 방법으로, 자원 사용량이 매우 적고 속도도 빠르다. 다른 하나는 클라이언트에서 처리한 후 데이터베이스로 자료를 전송해 데이터베이스에서 테이블로 Insert하는 방법이다. 이 방법은 ‘현재시간’처럼 쉽게 구할 수 있는 자료나 자료 생성 과정에서 서버에 존재하는 모듈을 반복 호출할 필요가 있을 경우에 사용하면 매우 효과적이다. 여기서는 편의상 첫 번째 방식은 <케이스 4-1>로, 두 번째 방식은 <케이스 4-2>로 칭한다. 양쪽을 모두 지칭할 때는 <케이스 4>로 칭한다. <케이스 4>에 필요한 소스도 ‘이달의 디스켓’으로 제공한다. <케이스 4-2>의 경우 Array 방식으로 전달받은 자료를 처리하기 위해 별도의 패키지가 필요하며 이 부분은 소스를 다운로드해 확인하기 바란다. <케이스 4>는 기존의 경우와 달리 OO4O로만 구현된다. 여기서는 OO4O를 이용한 각 케이스에 대해 소요시간과 자원 사용량을 비교해보자. <케이스 4> 이전에는 데이터베이스 서버에서 자료를 생성하고 생성된 자료를 Array 방식으로 테이블에 Insert를 하는 <케이스 3>이 가장 좋은 성능을 나타냈으며, 클라이언트에서 자료를 생성해 테이블에 Insert를 하는 <케이스 1>의 속도가 가장 떨어졌다. <케이스 4>는 <케이스 1>과 마찬가지로 클라이언트에서 자료를 생성하지만 자료 처리를 완료한 후 데이터베이스에 그 자료들을 한 번에 전송하기 때문에 <표 4>와 같이 빠른 처리가 가능했다(물론 이 시간은 데이터베이스의 소요시간으로 클라이언트의 처리 시간은 포함되지 않았다). <케이스 2>, <케이스 3>는 <케이스 1>에 비해 전체 소요시간이 단축되고 네트워크 사용량이 줄어드는 긍정적인 효과가 있었지만 데이터베이스 서버의 자원 사용량이 증가하는 문제가 발생했다. 반면 <케이스 4>는 자료 처리는 클라이언트에서 이루어지고 데이터 저장은 데이터베이스 서버 부분에서 처리하면서도 상당히 빠른 시간에 작업이 완료됐다. 물론 <케이스 4>에도 단점은 있다. <표 4>에서는 자료 처리가 이루어지는 클라이언트 부분의 소요시간과 자원 사용량이 표시되지 않았지만 실제로는 이보다 다소 많은 시간을 사용한다. 그러나 <케이스 3>에 비해 부하 분산과 높은 성능이라는 두 조건을 모두 만족하는 것이 사실이다. <케이스 4>는 자료가 클라이언트에서 생성되므로 네트워크를 통해 데이터베이스에 전송해야 한다. 따라서 자료가 데이터베이스에서 생성되는 <케이스 2>, <케이스 3>보다는 네트워크 I/O를 많이 사용할 수밖에 없다. 하지만 자료 1건을 생성할 때마다 네트워크 I/O를 수행해야 하는 <케이스 1>보다는 부담이 훨씬 적다. 이는 <화면 8>의 Wait 시간의 차이에서도 확인할 수 있다. 앞서 살펴본 바와 같이 <케이스 1>은 네트워크 I/O를 수행하며 27.59초의 시간을 소요한 반면 <케이스 4>는 채 1초가 되지 않았다. 자료가 생성되는 관점에서 <케이스 2>, <케이스 3>는 데이터베이스 서버에서 자료가 생성됐으며 클라이언트는 데이터베이스 서버의 프로시저를 호출하는 역할만 했기 때문에 네트워크 I/O의 사용량을 따지는 것은 의미가 없다. 한편 <화면 8>을 보면 <케이스 1>과 <케이스 4>의 SQL*Net mess age to client, SQL*Net message from client의 발생 횟수는 큰 차이를 나타낸다. 이들 값은 클라이언트에서 데이터베이스 서버 간에 네트워크 I/O가 몇 번이나 일어났는지를 나타내는 지표로, <케이스 1>은 2만 번이 넘지만 <케이스 4>는 단 3회에 불과했다. 이것은 클라이언트에서 데이터베이스 서버의 프로시저를 호출한 <케이스 2>, <케이스 3>과 동일한 수치다. 한 가지 차이점은 SQL*Net more data from client가 다수 발생했다는 사실이다. 이것은 클라이언트로부터 데이터베이스 서버로 대량의 자료가 입력되는 과정에서 발생한 것으로, <케이스 1>은 클라이언트에서 자료가 발생할 때마다 데이터베이스 서버로의 전송을 반복하고 자료량 자체보다는 네트워크 I/O에 따르는 오버헤드 때문에 상당한 시간이 소요됐으나, <케이스 4>는 생성된 자료를 1회에 전송해 효율적으로 작업할 수 있었다. 물론 자료량이 커서 전송 과정에서 SQL*Net more data from client라는 Wait Event가 발생했지만 그 시간은 무시해도 될 만큼 짧은 시간이다. 이제 데이터베이스 내부의 처리량을 살펴보자. 지난 호에서는 OraOLEDB를 사용하는 것으로 가정해 <케이스 1>, <케이스 2>, <케이스 3>를 비교했었다. 이번호에 추가된 OO4O를 사용하는 경우도 <케이스 1>에서부터 <케이스 3>까지는 비슷한 맥락이다. 관심있게 볼 부분은 <케이스 4>다. <표 5>를 보면 네트워크 사용량은 SQL*Net roundtrips to/from client 지표나 bytes received via SQL*Net from client 지표를 통해 <케이스 2>부터 <케이스 4>까지 <케이스 1>에 비해 매우 작은 값을 나타낸다. 특히 <케이스 1>과 <케이스 4>는 동일하게 클라이언트에서 자료를 생성하고 데이터베이스 서버의 테이블로 자료를 Insert하는 작업을 수행하지만, 상대적으로 <케이스 4>는 <케이스 2>, <케이스 3>과 마찬가지로 아주 적은 횟수로 네트워크 메시지를 주고 받았으며(SQL*Net roundtrips to/from client 참조), <케이스 1>에 비해 약 1/10 수준의 데이터를 받았음을 알 수 있다(bytes received via SQL*Net from client 참조). 서버 자원 사용률 측면에서는 <케이스 4-1>이 redo size, redo entries, session logical reads, session pga memory의 사용량이 감소됐다는 점이 가장 큰 특징이다. 특히 redo 관련 지표들이 크게 감소했는데, 이것은 그동안 어떤 방식의 테스트에서도 변화가 없었던 수치였다. 메모리 I/O 작업과 자료 변경 작업의 정도를 나타내는 session logical reads 역시 1/40 정도로 사용량이 떨어졌는데, 이것은 내부적으로 근본적인 처리 방법에 개선이 있었음을 의미한다. session pga memory도 <케이스 4-1>이 <케이스 3>에 비해 1/10 정도로 감소됐다. 반면 메모리 사용량에서는 <케이스 4-2>가 처리 과정에서 내부 변수에 값을 1회 더 할당해야 하기 때문에 오히려 증가했다. <케이스 3>은 처리 시간이 빨라졌지만 사용하는 메모리 량이 많이 증가했었는데, <케이스 4-1>은 이 문제까지 해소한 방안이었다. DB 성능, 연장보다는 사용방법이 결정 지금까지 2회에 걸쳐 MS 개발 환경에서 오라클 데이터베이스를 다루는 상황을 가정해 DAC별로 세 가지 방식으로 실제 수행 소요시간과 데이터베이스 내부의 자원 사용량을 비교해봤다. 데이터베이스의 성능과 관련된 지표들은 여러 가지가 있지만 여기서는 애플리케이션 서버와 데이터베이스 서버 또는 클라이언트 프로그램과 데이터베이스 서버 프로그램을 개발할 때 네트워크 I/O와 수행방식이 성능에 어느 정도의 영향을 미치는 지에 대해 살펴봤다. 결국 중요한 것은 연장이 아니라 이를 어떻게 사용하느냐 하는 것이다. 이 글이 데이터베이스 성능 문제로 고민하는 개발자들에게 도움이 됐기를 바란다.@ * 이 기사는 ZDNet Korea의 제휴매체인 마이크로소프트웨어에 게재된 내용입니다.