





TenG 주식회사는 내수와 수출을 같이하고 있는 가상의 조립제조 기업이다. IT 시스템 수요의 지속적인 증가에 따라 복잡성, 저활용 문제를 해결하기 위해 기업 그리드 컴퓨팅 환경을 구축키로 했다. TFT를 구성하고 전문가 집단에게 의뢰한 결과 '자동화'가 그 필수 요소라고 결론지었다. 자동화를 위한 기술요건으로 데이터 그리드, 저장장치 그리드, 데이터 프로비저닝 등 3가지를 검토한다.
이번 글에서는 데이터 그리드를 위한 자가 관리 데이터베이스 시스템에 대해 살펴 보자. IT 시스템이 비즈니스를 위한 전략적 요소로 부각되고 있는 가운데 ‘TenG 주식회사’ 또한 다음과 같은 과제를 설정했다.
[1] 모든 조직을 만족시킬 수 있는 IT 시스템의 가용성, 확장성 및 고성능 요구 사항의 증대
[2] 필요한 유지 보수를 위한 경우라고 할지라도 1년 365일 하루 24시간 지속적으로 운영
[3] 글로벌 기업으로 시스템 중단 시간은 이제 더 이상 용납할 수 없는 상황
[4] 복잡성으로 인해 시간, 노동, 잠재적 오류 및 장애 복구 실패 등의 측면에서 전반적인 비용 상승 초래
TenG 주식회사도 비즈니스의 전략적 부분인 자체 IT 시스템을 관리하는 것이 중요한 당면 과제여서 검토 끝에 해결책으로 ‘기업 그리드 컴퓨팅(Enterprise Grid Computing)’을 구축하는 것으로 결론지었다. 기업 그리드 컴퓨팅의 핵심은 산업 표준을 준수하는 모듈화된 스토리지와 서버들의 큰 연결체를 만드는 것이다. 이러한 새로운 아키텍처를 통해 각각의 새로운 시스템을 컴포넌트 풀로부터 신속히 공급할 수 있게 되며, 필요에 따라 리소스 풀로부터 용량을 쉽게 추가하거나 재할당할 수 있기 때문에 최대치(peak) 작업 로드를 위해 시스템 크기를 정할 필요가 없다.
TenG 주식회사는 점진적 비용 지출을 통해 모든 데이터센터 자원이 사용할 수 있는 많은 프로세싱 파워를 확보할 수 있게 됐다. 이를 통해 고속 처리 성능 및 고가용성은 물론 필요에 따라 확장할 수 있는 능력을 구현할 수 있게 된 것이다. 그러나 이것도 소프트웨어가 아키텍처를 효과적으로 이용할 수 있을 때 실현이 가능하다.
분명한 것은 이제 스스로 모니터링하고 관리할 수 있고, 비용 효과적으로 관리 복잡성을 줄일 수 있는 소프트웨어가 요구되는 시대가 도래한다는 것이다. 자가 관리형 소프트웨어가 없다면 전문 교육을 받은 수많은 관리자를 필요로 하는 복잡한 애플리케이션 및 이기종 시스템들이 기업의 성공적인 비즈니스 수행에 큰 장애물이 될 것이다. 그리고 관리 비용은 이로 인해 발생하는 문제점 중 일부에 불과하게 될 것이다.
다행스럽게도 TenG 주식회사는 이러한 기술적 과제를 정면으로 해결할 수 있도록 개발된 Oracle Database 10g를 적용해 신속한 처리 성능과 뛰어난 가용성을 제공할 뿐만 아니라 관리 비용을 줄일 수 있을 것으로 기대하고 있다. 데이터센터가 단순히 데이터베이스만이 아니라 컴포넌트 위치(데이터센터, 그리드 전반 및 전 세계적으로 분산 배치) 및 그 유형(스토리지, 클러스터, 애플리케이션 서버 등)에 관계없이 모든 컴포넌트를 관리할 수 있도록 지원하는 포괄적이고 기능이 다양한 전용 관리 툴을 제공한다. 이를 위해서는 무엇보다도 먼저 ‘자가 관리형 데이터베이스’를 구현해야 한다.
자가 관리형 데이터베이스의 구현
인텔의 공동 설립자인 고든 무어(Gorden Moore) 회장은 1965년 연설에서 “마이크로 칩의 처리 능력은 18개월마다 두 배로 증가한다”는 ‘무어의 법칙(Moore’s Law)‘을 발표했다. 이 법칙은 현재까지 맞아 떨어지는 것으로 최근의 IT 산업에 대한 여러 요소들을 결정하는 데 중요한 지표로 사용되고 있다. 이 중 데이터베이스 측면에서 최근 IT 산업의 나아가는 방향을 살펴보면, 관리해야 할 데이터베이스 개수의 지속적인 증가, 데이터베이스 크기의 기하급수적인 증가, 그리고 고효율, 저비용, 능동적인 문제점 감지, 분석 및 해결 등 많은 요소들이 있으며, 이러한 방향과 각각의 현상에 대해 알맞은 대응 방안을 모색해야 한다.
이러한 환경에 알맞게 대처하기 위해서 오라클은 기존 버전인 9i에서 10g로 가면서 가장 많은 노력을 할애한 부분이 ‘자가 관리 데이터베이스’이다. 문제 진단을 위해 DBA가 여러 스크립트들을 따로 돌릴 필요 없이 Oracle Database 10g가 알아서 진단해 주며, 이는 문제가 생기기 전에 미리 문제들을 감시?진단하는 역할을 하므로 DBA의 일이 한결 수월해진 것이다.
자가 관리 기반 구조
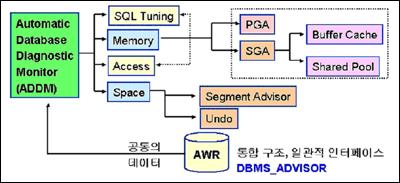
이러한 자가 관리 데이터베이스를 ‘TenG 주식회사’에서 활용하기 위해서는 우선 자가 관리 시스템이 어떤 방식으로, 어떤 요소들을 사용해 작동하는지 기본 아키텍처를 이해하고 이에 맞는 관리 정책을 세워야 한다. 따라서 자가 관리 데이터베이스의 핵심 기능인 자동 데이터베이스 진단 감시자(Automatic Database Diagnostic Monitor, 이후 ADDM)가 어떤 관리 기반 구조를 통해 데이터베이스 내에서 작동하는지 기본 원리를 알아본 후 실제 어떠한 상황에서 어떻게 적용할 지 실례를 통해 살펴보겠다.
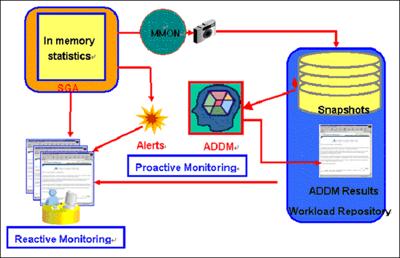
<그림 1>을 이해할 수 있다면 Oracle Database 10g가 어떤 방식으로 자가 관리를 하는지 전체적으로 이해한다고 볼 수 있다. 시스템의 메모리에는 SGA(System Global Area)에 자가 관리를 위해 필요한 정보들을 항상 관리하고 있고, 그 정보가 필요할 때 MMON(Manageability Monitor)이라는 Oracle Database 10g background process를 통해서 워크로드 리파지토리(Workload Repository)에 시간 단위를 기준으로 스냅샷 형태로 정보를 저장한다.
저장된 정보는 오라클 데이터베이스가 정한 기준에 따라 ADDM이 문제를 진단한다. 여기서 진단된 정보들은 EM(Enterprise Manager)을 통해서 DBA나 해당 사용자에게 정보를 보여준다. DBA가 문제를 파악하게 되면 이미 해결된 문제를 포함해 전체적으로 어떻게 정책을 세울지를 알게 된다.
ADDM이 제대로 동작하기 위한 구조
ADDM이 제대로 된 동작하기 위해서는 다음의 다섯 가지 관리 기반 구조가 필요하다. ADDM은 이런 다섯 가지 기반 구조를 유기적으로 이용해 데이터베이스의 자가 관리 기능을 수행한다. 그러면 각각의 구조에 대해 자세히 살펴본 후 이 기반 구조를 통해 ADDM이 어떻게 동작하는지 살펴보자.
[1] EM(Enterprise Manager)
[2] 자동 작업로드 저장(Automatic Workload Repository)
[3] 서버 생성 경보(Server-generated Alerts)
[4] 관리 작업 자동화(Automated Maintenance Tasks)
[5] 권고자 프레임워크(Advisory Framework)
Enterprise Manager
Oracle Database 10g의 새로운 기능인 EM은 데이터베이스를 관리하기 위해 필요한 모든 정보 및 변경 사항 들을 HTML 방식으로 보여주는 툴이다. HTML 방식으로 보여 주기 때문에 웹 브라우저로 원하는 모든 정보를 볼 수 있다. EM을 활용하는 자세한 예는 뒤에서 살펴보기로 하고 EM의 두 가지 종류를 살펴보기로 하자. EM은 데이터베이스 컨트롤과 그리드 컨트롤의 두 종류로 나뉜다.
데이터베이스 컨트롤은 요청하는 정보가 하나의 데이터베이스일 때 사용되는 EM이다. 즉, 가장 일반적인 형태의 관리 툴이라고 보면 된다. 데이터베이스 컨트롤은 데이터베이스 내에는 자동 작업로드 저장소에 있는 정보를 매니지먼트 서비스를 통해서 요청한다. 요청한 정보들은 웹 브라우저를 통해서 볼 수 있다.
데이터베이스 컨트롤의 확장된 버전이 그리드 컨트롤이다. 서로 관련이 있거나 관련이 없는 여러 데이터베이스의 정보를 한 화면에서 볼 수 있게 만든 것이 그리드 컨트롤이다. 각각의 자동 작업 로드 저장소는 각각의 서버에 저장해 놓고 관리해 주는 매니지먼트 서비스를 따로 하나의 서버에 두는 방식이다(매니지먼트 서비스를 데이터베이스를 사용하는 서버에 놓을 수도 있다). 이럴 경우 여러 데이터베이스의 정보를 보는 데 병목 현상이 일어나지 않으며, 필요한 정보들을 매니지먼트 서비스가 요청하고 관리하기 때문에 부하를 분산시킬 수 있다.
자동 작업 로드 저장소
ADDM이 정보를 분석하기 위해서는 두 가지 정보를 필요로 한다. 하나는 시스템의 메모리에 있는 SGA의 실시간 통계 정보이며, 다른 하나는 지난 시간의 정보를 갖고 있는 자동 작업 로드 저장소의 정보이다. 시스템의 메모리 크기는 디스크 크기에 비해 적은 양의 정보를 갖고 있고, 시스템이 재부팅되거나 오라클 데이터베이스가 다운되면 메모리의 정보들은 사라지기 때문에, 여러 정보들을 분석해 결과를 도출하기 위해서는 디스크의 정보를 필요로 한다.
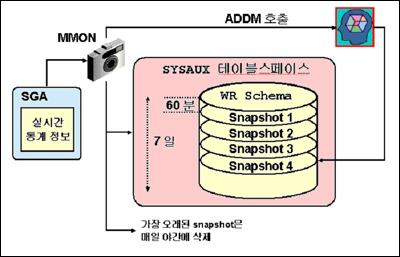
자동 작업 로드 저장소의 정보는 SYSAUX 테이블스페이스에 스냅샷의 형태로 저장된다. 즉, Manageability Monitor라는 Oracle Database 10g background process에 의해 정해진 주기 단위로 SGA의 정보들을 사진기가 사진을 찍듯이 필요한 정보들을 SYSAUX 테이블 스페이스에 저장하게 된다. 이러한 주기 단위는 원하는 시간으로 조절이 가능하다.
또한 이러한 스냅샷은 일정량의 디스크를 필요로 하기 때문에 무한정 정보를 저장할 수 없다. 따라서 일정 기간의 보관 주기가 필요하다. 이 보관 주기 또한 변경이 가능하다. 하나의 스냅샷 크기는 250KB 정도가 되므로, 1시간 마다 스냅샷을 찍고 7일간 보관 주기를 갖고 있을 경우, 250KB× 24×7=42MB 정도의 디스크가 필요하다.
여기서 한 가지 중요한 점은 보관 주기가 존재할 때 어떤 특정한 시간의 스냅샷을 보관하고 싶을 경우에 보관 주기가 지나버리면 그 스냅샷이 사라진다는 문제가 있다. 특정한 시간의 스냅샷을 보관하는 이유는 그 스냅샷이 특이한 현상을 보일 때의 중요한 정보들을 갖고 있거나, 관리자가 원하는 이상적인 형태로 운영될 때 등 여러 이유가 있을 수 있으며, 그러한 정보들을 원할 경우 계속 보고 싶기 때문이다. 하지만 이럴 경우를 대비해 베이스라인이라는 방법이 존재한다. 즉, 베이스라인 방법을 사용해 특정 시점의 스냅샷들을 지정해 보관 주기와 상관없이 SYSAUX 테이블 스페이스에 영구히 보관할 수 있다.
◆ AWR에 저장되는 정보
- 기본 통계 정보
- Metric
- 세션 활동 기록
- 시간 모델 통계 정보
- OS 통계 정보
- 데이터베이스 사용 통계
그럼 AWR에 저장되는 정보들에 대해 살펴보자.
기본 통계정보
이 정보들은 Oracle Database 10g 이전 버전에도 갖고 있었던 정보들이다. 즉, 어떤 활동이 있을 때 그 활동들의 누적치이다. 이러한 기본 통계들의 문제점은 하나의 활동에 대한 누적치이기 때문에 각각의 시간마다 변화된 정도를 알 수 없다는 점이다. 예를 들어, 어떤 한 블럭에 대한 읽기 정보를 살펴보자. 처음 오후 1시까지 총 읽은 수는 10번이었다. 1시간이 지난 후 읽은 횟수가 100번으로 늘어나 있을 경우, 관리자가 오후 1시경의 정보를 기록하고 있지 않은 한, 1시간이 지난 후의 100번의 읽은 횟수는 여태껏 데이터베이스가 구동된 후 총 읽은 횟수를 의미하기 때문에 변화량을 알 수 없는 것이다. 이러한 정보들을 보완하기 위해 생긴 정보가 Metric이다.
Metric
앞에서 설명한 바와 같이 Metric의 정보는 각각의 정보들을 특정 단위로 기록한 정보이다. 즉, 초 단위로 physical read가 일어난 횟수, 트랜잭션 단위로 physical read가 일어난 횟수 등 단순한 누적치가 아니라 일정 기준을 갖고 변화된 양을 표현해 준다. 이럴 때 시스템에 문제가 될 경우 혹은 문제가 일어날 소지가 있을 경우를 정확히 파악해 어떤 점에 문제가 있었는지 알 수 있다.
세션 활동 기록
세션활동 기록(Active Session History-ASH)은 매 초 단위로 현재 활동 중인 세션에 대한 정보를 V$ACTIVE_SESSION_HISTORY에 저장한다. 저장되는 세션 정보는 세션에 대한 기본 정보, wait event, 실행하는 SQL문의 간단한 정보 등으로, 필요시 MMON에 의해 AWR에 기록된다.
시간 모델 통계 정보
Oracle Database 10g의 튜닝 방법은 다음과 같은 공식을 기반으로 한다.
Response Time = Service Time + Wait Time
따라서 이러한 방법의 튜닝을 하려면 이 방법에 맞는 정보들을 갖고 있어야 한다. 즉, AWR에 생성되는 정보들은 이 튜닝 방법에 맞는 정보들을 보관하고 있다. 앞의 공식이 어떻게 활용되는지는 ADDM이 동작하는 방법을 설명할 때 더 자세히 설명하겠다.
OS 통계 정보
Oracle Database 10g 이전 버전과의 큰 차이점 중 하나가 바로 이 부분이다. 데이터베이스가 데이터베이스 서버라고 불려지지만, 데이터베이스 또한 OS 위에 돌아가는 하나의 애플리케이션에 불과하다. 따라서 모든 문제의 근원은 OS와 연계되어 있는 것이다. 즉, 어떤 문제를 해결하거나 문제가 될만한 상황은 OS 정보가 필요할 경우가 많기 때문에, Oracle Database 10g부터 OS 정보 또한 보관하고 있다.
데이터베이스 사용 통계
데이터베이스 사용 통계는 다른 모든 정보들을 종합해 얻어낼 수 있는 정보들이다. 그러나 데이터베이스 사용 통계들은 매우 많이 쓰이는 정보로, 필요할 때 마다 모든 정보들을 종합해 계산하는 것은 데이터베이스 자체 내에 매우 많은 부하를 줄 수 있으므로 그 때 그때 필요한 데이터베이스 사용 통계를 AWR에 저장시켜 놓는다.
서버 생성 경보
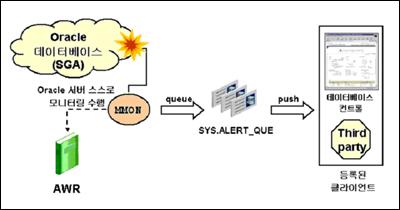
서버 생성 경보(Server-generated Alerts)는 오라클 데이터베이스가 자동적으로 경보를 보낼 상황을 발견해 문제에 대한 상세한 설명과 그에 따른 조언을 AWR에 저장하는 자가 관리 기반 구조이다. 이 정보들을 주기적으로 수행되는 MMON과 다른 여러 Oracle foreground processor에 의해 감지되며, 감지된 내용들은 SYS 스키마에 등록된 ALERT_QUE라는 이름의 큐(queue)에 쌓이게 된다. ALERT_QUE에 쌓여진 문제들을 상황에 맞게 DBA가 해결하게 되면, alert history에 쌓여진 정보들은 사라지게 된다. 또한 AWR 보관 주기를 넘긴 alert들도 자동적으로 사라진다.
서버 생성 경보의 종류에는 두 가지가 있다. 하나는 임계 값을 갖는 경보로서 AWR에 쌓인 여러 Metric 정보들을 기준으로 생성된다(161개의 Metric 정보들이 이러한 임계 값 기준 경보 생성에 사용될 수 있다). 임계 값을 기준으로 생성되는 경보는 주의와 위험 두 가지 기준을 가진다.
예를 들어 테이블스페이스의 공간 사용량이 85%이면 주의 경보를, 95%이면 위험 경보를 주는 어떤 특정한 기준을 가진 값을 설정할 수 있다. 이렇게 생성된 임계 값 기준 경보는 DBA_OUTSTANDING_ALERTS에 쌓이며 경보를 만든 임계 값 이하로 해당 내용을 만들어 주면 경보가 해제되고 DBA_ALERT_HISTORY에 쌓이게 된다. 서버 생성 경보의 다른 한 종류는 비임계 값 경보이다. 이는 특정한 임계 값을 설정할 수 없는, 즉 특정한 이벤트가 발생될 때 생기는 경보로써 이러한 문제가 발생되면 바로 DBA_ALERT_HISTORY에 정보가 쌓이게 된다.
다른 여러 임계 값이나 비임계 값 서버 생성 경보 기준을 설정할 수 있으며, Oracle Database 10g를 처음 설치했을 때, 기본적으로 생성되어 있는 경보들은 다음과 같다.
[1] 테이블 스페이스 사용 정도 - 주의(warning) 85%, 위험(critical) 97%
[2] Snopshot Too Old
[3] Recovery Area Low On Free Space
[4] Resumable Session Suspended
관리 작업 자동화
Oracle Database 10g는 DBA가 일정한 시간마다 실행시켜야 할 여러 작업을 정의하기 위해 스케쥴러(scheduler)라는 새로운 기능을 보여준다. 이는 기존 버전의 DBMS_JOB의 향상된 형태이다. Job은 관리 작업 자동화 모듈에서 직접 실행되는 작업이다. 이러한 작업들은 ‘Enabled’되어 있을 경우에만 실행되며, 모든 job들은 Job Class에 속해 있다.
Job class는 이러한 job들의 정의만을 갖고 있으며 관리자에 의해 정보가 변경되지 않으면 사실상 정적인 정보이다. 실행 중에 변경되는 정보들은 컨슈머 그룹(Consumer group)에서 관리해준다. 이러한 job들은 매니지먼트 윈도우(Management Window)나 윈도우 그룹(Window group)에 속하게 되며, 매지니먼트 윈도우는 실행되는 시간 값을 갖고 있다. 즉, job의 실행 시간을 해당 매니지먼트 윈도우를 통해서 관리해 준다.
매니지먼트 윈도우는 또한 각각의 job의 실행 기준을 리소스 플랜(Resource plan)으로 정하게 된다. 리소스 플랜은 컨슈머 그룹의 정보를 이용해 실행 기준을 만들며 그러한 실행 기준을 매니지먼트 윈도우에 전달한다. 매니지먼트 윈도우와 윈도우 그룹의 차이점은 리소스 플랜을 가지고 있는 지의 여부이다. Consumer Group은 Job class의 정보를 이용해 무엇이 실행되고 있는지를 검사한다. 실제적인 예를 들어 살펴보자.
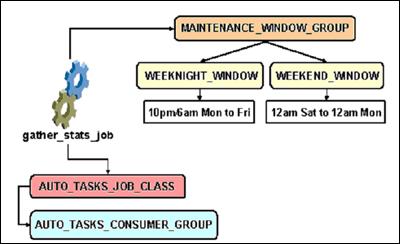
통계 수집 작업의 예
Oracle Database 10g의 기본적인 통계 수집 작업을 예로 살펴보자. WEEKNIGHT_WINDOW와 WEEKEND_WINDOW는 윈도우의 이름과 같은 시간 단위로 실행되는 윈도우이다. 이러한 윈도우들은 각각 MAINTENANCE_WINDOW_GROUP이 관리해 주며, 실제 실행되는 주체인 gather_stats_job이라는 job이 AUTO_TASKS_JOB_CLASS에 속해 있고, 이 클래스는 AUTO_TASKS_CONSUMER_GROUP에 속해 있고, MAINTENANCE_WINDOW_GROUP이 윈도우 관리에 필요한 정보를 갖고 있다.
즉, 통계 수집이 매일 밤, 그리고 매 주말마다 이뤄지고 있으므로, DBA는 특별히 통계 작업에 대해 걱정할 필요가 없다. 해당 시스템마다 작업량이 몰리는 시간을 피하기 위해서는 이러한 윈도우의 시간 정보만 변경해주면 된다. 또한 이러한 윈도우 말고도 다른 윈도우를 필요로 할 경우 EM을 통해서 쉽게 생성할 수 있다.
어드바이저 프레임워크
어드바이저 프레임워크는 <그림 5>를 보면 크게 네 개로 나뉘는 것을 알 수 있다. 각각의 어드바이저는 다음의 세 가지 방법에 의해 호출된다.
[1] AWR 스냅샷이 생성될 때, 필요시 MMON에 의해 호출된다.
[2] 서버 생성 경보가 생성될 때, 필요한 권고를 위해 호출된다.
[3] 어드바이저 위저드(wizard)를 통해서 DBA가 필요시 직접 호출할 수 있다.
이러한 방식으로 호출되는 권고자는 제한 모드와 비제한 모드로 나뉠 수 있다. 권고자는 더 자세히 조사할수록 좀 더 정확한 권고를 생성하게 된다. 따라서 어떤 제한을 두어서 그 이상은 조사를 하지 않도록 제한을 둘 수 있고, 제한을 가하지 않고 권고자가 알아서 수행하도록 놓아 둘 수 있다.
이러한 제한 모드는 시간 제한(Time Limit), 방해 제한(Interruptible), 그리고 사용자 지시 제한(User Directive)의 세 가지 방식이 존재한다. 앞의 세 가지 제한 모드가 모든 권고자에 적용될 수 있는 것은 아니다. 그러면 이러한 권고자 각각에 대해 자세히 살펴보도록 하자.
SQL 튜닝 어드바이저
이름 그대로 SQL 튜닝에 대한 권고를 생성하는 어드바이저이다. SQL 튜닝 권고자는 크게 네 가지의 일을 한다.
[1] Statistics Analysis : 필요한 통계 자료가 오래됐다거나 생성되어 있지 않을 경우 자동으로 통계자료를 모은다.
[2] SQL Profiling : CBO(Cost Base Optimizer)로 수행될 때 SQL문을 위해서는 부가 정보들이 필요하다. 이러한 SQL문의 정보들을 SQL 프로파일이라는 형태로 수집해 놓는다. 이러한 SQL 프로파일이 필요할 때마다 SQL 튜닝 어드바이저에 의해 업데이트된다.
[3] Access Path Analysis : 어떤 인덱스를 통해 데이터를 접근할 지를 결정해 준다. 필요시 SQL 액세스 어드바이저를 호출해 인덱스에 대한 권고를 요구하기도 한다.
[4] SQL Structure Analysis : SQL문이 비효율적인 플랜을 생성할 경우, 똑같은 결과를 보여줄 수 있는 비슷한 SQL문을 생성해 권고를 주는 역할을 한다.
SQL 튜닝 어드바이저가 이런 일을 자동으로 수행해주지 않을 경우, 각각에 대해 오른 쪽과 같은 일을 관리자가 해줘야 한다. 이런 일은 관리자의 일을 가중시키거나 때로는 잘못된 정보를 산출해 내기도 한다. 따라서 SQL 튜닝 권고자에게 이런 일련의 일들을 맡기면 업무를 감소시키고 잘못된 정보를 산출할 일이 없어지게 된다.
SQL 액세스 어드바이저
SQL 액세스 어드바이저의 경우 인덱스에 관계된 권고를 생성한다. 가령 인덱스의 접근 빈도를 보고, 어떤 인덱스를 시스템에서 전혀 필요 없는 인덱스임을 권고로 제시할 수 있으며, 어떤 인덱스들은 두 가지를 합쳐 하나의 인덱스로 생성하도록 권고를 낼 수도 있으며, 인덱스에 대한 여러 권고를 생성하는 권고자이다.
메모리 어드바이저
메모리 어드바이저는 오라클 데이터베이스에 관련된 모든 메모리를 관리해주는 역할을 하는 것으로, 크게 PGA 권고자와 SGA 권고자로 나뉜다. 또한 SGA 권고자는 버퍼 캐시(Buffer Cache) 권고자와 라이브러리 캐시(Library Cache) 권고자를 포함하고 있어서 각각은 해당 메모리에 대한 권고를 생성한다.
그러면 SGA와 관련된 새로운 기능 및 그 기능에 대한 SGA 권고자 자동 관리에 대해 살펴보자. 기존 SGA는 초기 파라미터 파일에 근거해 그 크기가 결정되면 크기 변경이 불가능했다. 몇 가지 메모리에 대해서는 크기 조정이 데이터베이스를 내리지 않고도 가능했으나 전체적으로 크기를 조정하기 위해서는 데이터베이스를 내렸다가 올려야 하는 번거로움이 있었다. 그러나 Oracle Database 10g부터 SGA_TARGET을 설정해주면 리두 로그 버퍼(redo log buffer)와 Fixed SGA를 제외한 모든 SGA 메모리 크기가 SGA 메모리 어드바이저에 의해 능동적으로 변경된다.
세그먼트 어드바이저
세그먼트 어드바이저의 가장 큰 권고는 데이터베이스의 데이터양의 생성 정도이다. 데이터베이스의 데이터양의 증가 정도에 따라 디스크가 향후 얼마만큼 필요할 지 권고해주며, 또한 각 세그먼트가 조각들이 많이 생겨 I/O 효율이 떨어질 경우 segment shrink 권고를 생성해준다.
언두 어드바이저
언두(Undo) 어드바이저는 세그먼트 어드바이저와 비슷하지만, 단지 언두 테이블 스페이스 및 언두 세그먼트에 관계된 권고만을 생성한다. 이러한 내용들은 나중에 EM 화면을 통해서 살펴보면 확실히 이해할 수 있을 듯 하다.
자동 데이터베이스 진단 감시자
ADDM이 동작하기 위해 그 많은 자가 관리 기반 구조를 설명했다. 이제는 이 자가 관리 기반 구조를 바탕으로 ADDM이 어떻게 동작하는지 알아볼 차례이다. 사실 자가 관리 기반 구조에 대한 설명을 자세히 읽어본 독자라면 ADDM이 어떻게 동작하는지 이미 이해하고 있을 것이다.
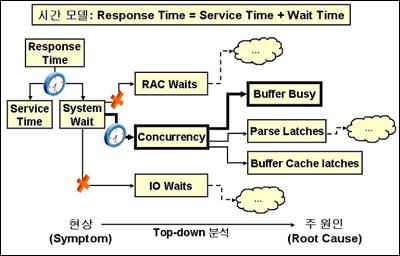
자동 데이터베이스 진단 감시자는 한마디로 표현하면 데이터베이스 내의 DBA이다. 데이터베이스의 성능을 항상 감시하고 있으며, 필요시 해당 권고자를 호출하며 때로는 ADDM이 알아서 권고를 생성하게 된다. 어드바이저의 권고를 비롯해 ADDM이 생성하는 모든 권고들은 오라클의 전문가들이 수십 년간의 기술 및 정보들을 하나의 체계에 의해 분류해 놓은 참고서와 같은 자료들이다. 이 체계는 앞에서도 말했지만 <그림 6>와 같은 시간 모델을 근거로 한다.
모든 튜닝의 기준은 <그림 6>에 나와 있는 것과 같이 Response Time=Service Time+Wait Time을 근거로 한다. 이러한 기준을 바탕으로 탑다운 방식으로 문제를 접근해 나간다. <그림 6>에 나와 있는 예로 어떤 특정 현상에 대해 문제가 있는지 조사할 경우 Wait Time에서 문제시 될만한 점이 발견됐다. 이는 다른 현상과는 상관없는 Concurrency 문제로 좁혀졌고, 나아가서 Buffer Busy에 문제가 있음을 각각의 세부 원인을 통해 알게 됐다. 정확한 분류 체계 아래, 탑-다운 방식으로 문제를 찾아 나가면 결국 문제의 원인 및 권고를 찾는 일은 어렵지 않다.
ADDM이 감지하는 주요 성능 이슈는 이전 버전의 STATSPACK에서 보여줬던 여러 요소들을 포함해 Oracle Database 10g에서 새로 보여 주는 여러 정보들이 있다. ADDM에 의해 감지되는 주요 문제점 중 다음의 부분은 STATSPACK에 의해 감지되지 않는 부분들을 보여준다.
◆ ADDM이 감지하는 주요 문제점
Excessive logon/logoff Memory undersizing
Hot blocks and objects w/SQL RAC service issues
Locks and ITL contention Checkpointing causes
PL/SQL, Java time Top SQL
I/O issues Parsing
Configuration issues Application usage
자가 관리 데이터베이스 활용
자, 이제껏 읽어 온 내용은 바로 이번 장을 보여 주기 위해서 기본 정보를 준 것이었다. 실제 보여주고 싶었던 내용은 TenG 주식회사의 DBA인 ‘그리드’군이 Oracle Database 10g를 사용해 어떻게 데이터베이스를 관리하는지 보여주기 위해서였다. 그럼 ‘그리드’군의 하루를 통해 Oracle Database 10g의 자가 관리 기능을 어떻게 사용하는지 보기 바란다.
TenG 주식회사의 DBA인 ‘그리드’군의 하루
‘그리드’군은 TenG 주식회사를 다니는 DBA이다. TenG 주식회사의 데이터베이스를 관리해 온지 이제 5년이 갓 넘은 ‘그리드’군은 여태껏 나름대로 열심히 자신의 실력을 닦아 온 터라 자신의 실력을 믿고 있는 기술자이다. 그러나 최근 1년간 회사의 IT 시스템의 급속한 증가 및 복잡성, 그리고 인력 부족의 문제점 등으로 매우 힘든 나날을 보내고 있었다. 그러던 중 Oracle Database 10g의 그리드 기술을 통한 자가 관리 기능의 우수성을 듣고, TenG 주식회사의 시스템을 Oracle Database 10g로 바꾸기 위해, 여러 시스템 중 하나를 Oracle Database 10g로 업그레이드해 시범 운영 중이다.
‘그리드’군은 오늘도 여느 때와 마찬가지로 시스템 관리를 위한 문제 분석으로 하루 일과를 시작하였다. Oracle Database 10g의 자가 관리 기능의 강력함을 느껴왔던 터라 오전에 끝낼 수 있다는 자신감을 갖고 있었지만, 오후 1시의 회의 후 내용에 대한 검토 및 실행은 얼마가 걸릴지 몰라 일단 오후 시간은 비워 놓은 터였다.
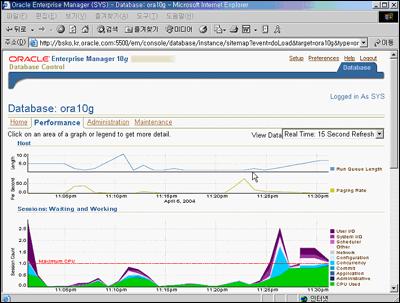
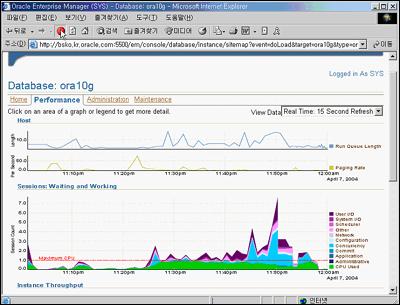
우선 EM을 통해 현재 DB가 어떤 상태인지 성능 부분을 살펴봤다. 그런데 20분 정도 전부터 과도한 시스템 사용이 발견됐다. <화면 1>을 보면 많은 양의 CPU 사용과 concurrency 사용이 있다는 것을 알 수 있다.
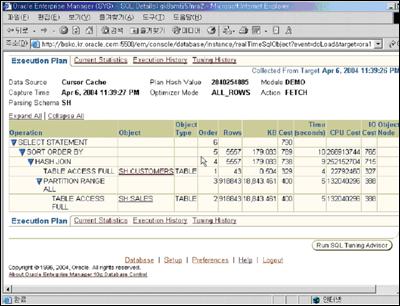
좀 더 아래쪽을 살펴보니, 사용자 I/O가 많음을 확인할 수 있었다. 따라서 이러한 사용자 I/O가 어떤 SQL문에 의해 일어나는지 좀 더 아래 쪽 화면을 보고 알 수 있었다. 또한 SQL 활동의 76%를 차지하는 SQL문을 볼 수 있었다. 이 SQL문을 클릭하면 좀 더 자세한 정보를 얻을 수 있다. <화면 2>와 같이 이 SQL문이 어떤 execution plan으로 풀리며 어느 정도의 I/O를 발생시키는지 확인해봤다.
그럼 이제 SQL 어드바이저를 실행시켜 권고가 어떻게 나오는지 확인해 본 후, 생성된 권고를 적용하는 버튼만 눌러 <화면 3>과 같이 데이터베이스의 부하가 현저하게 감소함을 볼 수 있다.
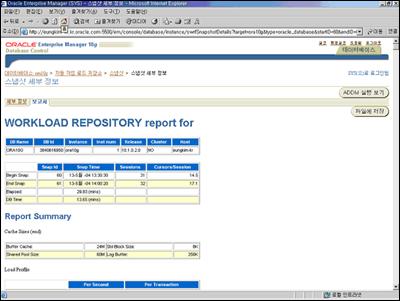
이렇게 문제를 해결한 ‘그리드’군은 오늘 오후 회의를 위해 전반적인 시스템을 살펴보기 위해 EM을 통해 <화면 4>와 같이 리포트를 만들었다.
이렇게 회의 준비를 마친 ‘그리드’군은 회의를 예정대로 2시경에 끝냈다. 회의 내용은 현재의 디스크 사용량을 검사하고, 급한 부분은 임의로 크기를 늘린 후 향 후 얼마나 디스크가 필요할 지 예측하기로 했다.
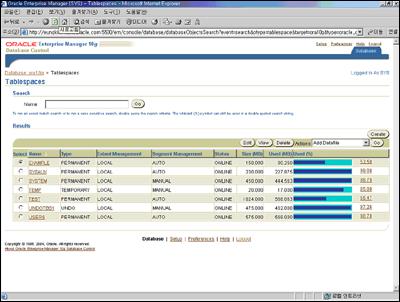
관리 화면의 테이블 스페이스를 보면 <화면 5>와 같이 대부분의 테이블 스페이스가 용량이 다 차 있음을 확인한 ‘그리드’ 군은 일단 시급한 부분이 언두 테이블 스페이스라고 판단해 언두 권고자를 통해 얼마나 늘려야 할지를 예측해 봤다. EM의 언두 어드바이저의 권고를 바탕으로 앞으로 얼마만큼의 데이터양이 데이터베이스에 쓰일지 예측하면 어느 정도의 언두 테이블 스페이스가 필요할 지 알 수 있었다. 또한 회의에서 나온 여러 내용을 EM을 통해 손쉽게 해결했다.
자가 관리 기능의 중요성
관리자의 모든 문제가 앞에서 설명한 예와 같이 쉽게 해결되는 것은 아니다. 그러나 여기서 보여주고자 하는 내용은 Oracle Database 10g를 통해 기존의 일이 얼마만큼 쉽게 풀리는가 하는 것이다. 이런 맥락에서 보면 ‘그리드’군의 예는 전혀 과장된 내용이 아니며, 앞으로 Oracle Database 10g의 자가 관리 기능을 사용함으로써 당연히 이뤄질 수 있는 것이다.
한 가지 아쉬운 점이 있다면, 지면 제약상 좀 더 자세히 여러 문제에 대해 EM의 많은 캡처 화면을 보여주지 못했다는 것이다. 관리적인 측면에서 Oracle Database 10g는 모든 일을 EM을 통해서 다룰 수 있다. 모든 화면을 일일이 캡처해 보여주는 것은 너무나 많은 지면을 필요로 한다.
따라서 인지할 사항은 앞으로 Oracle Database 10g를 통해 관리자는 시스템을 효율적으로 관리할 수 있다는 것이다. 관리의 많은 부분이 자동으로 실행되며, 원하는 모든 업무를 Oracle Database 10g를 통해서 스케쥴을 만들어 분할 및 실행할 수 있다. 자가 관리 외에 다른 부분은 다음에 연재되는 내용을 토대로 좀 더 상세히 알아보도록 하자. @

지금 뜨는 기사
이시각 헤드라인




ZDNet Power Center
