





일반적으로 사람들이 아는 것과는 달리 관계형 데이터베이스 표준 언어인 SQL은 데이터 분석을 목적으로 만들어지지 않았다. 따라서 아주 간단한 데이터 분석을 위한 질의 작성을 어렵게 만들고 질의 수행 속도도 느리다는 단점이 있다. 이런 SQL의 단점을 극복하기 위한 노력들이 최근에 활발히 이뤄지고 있으며, 대표적인 예로서 최근에 SQL3 표준에 도입된 분석 함수(참고자료 : [Andrew Witkowski et al., Spreadsheets in RDBMS for OLAP, Proceedings of SIGMOD, 2003])가 있다.
이러한 맥락에서 이 글에서는 최근에 특정 관계형 DBMS 벤더에 의해 제안된 SQL의 확장 기능에 대해 설명하고자 한다. 이 확장 SQL은 엑셀과 같은 스프레드시트 도구에서 데이터 분석을 위해 제공되는 특징들을 DBMS에서도 가능하도록 하는 획기적인 기능이다. 즉, 엑셀과 같은 스프레드시트 도구에서 제공하는 ‘2차원 배열 데이터에 대한 계산 기능을 하나의 SQL문으로 표현 가능하도록’ SQL을 확장하는 것이다.
엑셀과 SQL의 공통점과 차이점
엑셀과 SQL의 공통점은 무엇일까? 둘다 2차원 표에 포함된 데이터-엑셀의 경우 스프레드시트, SQL의 경우 릴레이션(또는 테이블)-를 대상으로 데이터를 분석하는 데 사용될 수 있다는 점이다. 그럼 가장 큰 차이점은 무엇일까? 엑셀은 누구나 조금만 배우면 직관적으로 다양하고 복잡한 분석 기능을 아주 훌륭한 사용자 인터페이스 하에서 수행할 수 있다는 점이다. 그러나 데이터 크기가 일정한 이상을 넘어가게 되면 처리할 수 없다는 단점이 있는 반면, SQL은 현재 테라(tera) 이상의 데이터를 처리할 수 있다.
독자들도 주지하다시피 스프레드시트는 많은 사람들이 사용하는 가장 성공적인 데이터 분석 도구이다. 행(row)과 열(column)로 구성된 2차원 배열에 데이터를 입력하고 다음과 같은 다양한 조작을 수행할 수 있다.
◆ 재귀적 모델(recursive model)을 지원하는 수식 지원
◆ 선택된 셀 또는 셀의 범위에 대해 분석 함수와 집단 함수(aggregate function) 제공
◆ 사용자가 사용하기 편한 훌륭한 사용자 인터페이스
반면, 엑셀 이상으로 성공적인 관계형 DBMS의 대표 언어 SQL은 분석적인 기능 측면에서 최근의 큐브(cube) 개념과 분석 함수(analytic functions)의 도입에도 불구하고 엑셀과 같은 스프레드시트 도구의 앞과 같은 기능에 비교하면 아직까지 부족한 부분이 있다. 부족하다는 측면은 2차원 배열을 대상으로 한 복잡한 계산을 표현하기가 (불가능하지는 않지만) 힘들고, 이를 대량의 데이터에 대상으로 수행하게 되면 비효율적으로 처리된다는 점이다. 그렇지만 엑셀을 포함한 스프레드시트 도구들도 나름대로의 문제점을 내포하고 있다. 대표적으로 다음과 같은 세 가지 문제가 있다.
◆ 확장성(scalability) : 데이터의 양이 아주 크거나 공식의 수가 굉장히 많을 때 분석이 원활하지 못하다.
◆ 다중 스프레드시트에 대한 통합 분석(collaborative analysis) : 별도로 분석된 두 개 이상의 스프레드시트들의 통합 분석이 용이하지 못하다.
두 훌륭한 소프트웨어를 결합하는 방안은 ① 엑셀이 대용량 데이터베이스의 기능을 갖거나 ② SQL 언어에서 엑셀과 같은 다양하고 복잡한 분석 기능을 사용자가 쉽게 사용할 수 있도록 추가하는 방법이 있을 것이다. 이 글에서는 엑셀의 문제점들을 극복하면서 동시에 앞서 설명한 엑셀의 2차원 배열 기반 분석/계산 기능을 관계형 데이터베이스 표준인 SQL에 자연스럽게 접목하기 위한 하나의 확장 방안을 알아본다(이 글에서 설명하는 내용은 최근에 특정 관계형 DBMS 벤더에 의해 제안된 것으로 참고자료 [Andrew Witkowski et al., Spreadsheets in RDBMS for OLAP, Proceedings of SIGMOD, 2003]를 참고했다). 또한 SQL이 이러한 기능을 추가하게 되면 데이터 분석의 아키텍처가 어떻게 바뀌고 어떤 장점이 있는지를 살펴보겠다.
SQL이 엑셀을 만날 때
SQL에서 스프레드시트 기능을 지원하게 되면(즉, SQL에 엑셀 기능을 흡수했을 때) 스프레드시트 기반의 데이터 분석 아키텍처에 어떤 변화가 생긴다. 관계형 데이터베이스 내에 존재하는 데이터를 분석하는 비즈니스 데이터 분석가들은 현재 <그림 1>의 아키텍처대로 데이터 분석 과정을 거친다.
관계형 데이터베이스로부터 필요한 데이터를 정의하고 이 데이터를 파일 전송이나 엑셀에서 제공하는 ODBC 인터페이스를 이용해 데이터를 엑셀로 불러들인다. 이렇게 불러온 데이터를 이용해 엑셀의 다양한 분석 기능을 이용해 분석 스프레드시트를 생성하고 이를 파일 형태로 저장해 둔다.
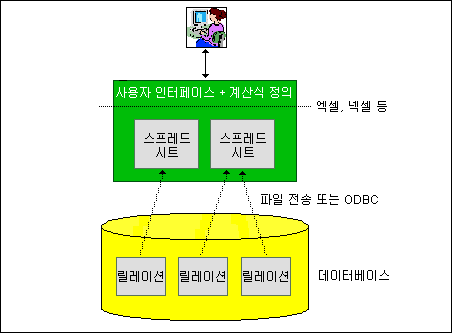
<그림 1> 엑셀과 관계형 DBMS 연동 : 현재
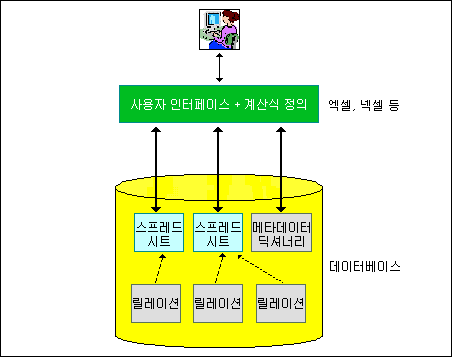
<그림 2> 엑셀과 관계형 DBMS 연동 : 미래
그러나 SQL에서 스프레드시트 기능을 지원하게 되면 궁극적으로 <그림 2>와 같은 방식으로 엑셀과 관계형 데이터베이스가 연동하게 될 것이다. 관계형 데이터베이스 릴레이션에 저장된 데이터를 기반으로, 사용자가 여러 가지 분석 기능을 포함하는 스프레드시트를 정의하면(이 경우 하나의 스프레드시트는 하나의 SQL문으로 표현됨) 그 스프레드시트는 일반 데이터와 마찬가지로 관계형 데이터베이스 내에 존재하게 된다. 해당 스프레드시트의 데이터는 특수한 릴레이션 행태로 데이터베이스에 저장되고 스프레드시트의 정의는 관계형 데이터베이스의 메타데이터 딕셔너리에 저장된다. 엑셀 등의 도구는 데이터 저장 및 분석을 위한 계산 기능을 DBMS에게 넘겨주고 자신은 거의 사용자 인터페이스만 담당하는 역할을 하게 될 것이다.
SQL에 엑셀의 분석 기능 추가하기
지금부터 참고자료 [Andrew Witkowski et al., Spreadsheets in RDBMS for OLAP, Proceedings of SIGMOD, 2003]에서는 엑셀의 분석 기능을 관계형 DBMS에 추가하기 위해 SQL을 어떻게 확장했는지 알아보도록 하자. 이에 앞서 이 글의 나머지 부분에서 사용하게 될 예제 데이터를 설명하겠다. <표 1>은 릴레이션 f(r, p, t, s, c)의 스키마와 데이터를 보여주고 있다(r, p, t, s, c는 각각 region, products, time, sales, cost의 약자다). 이 테이블은 west/east 지역에서 TV/Video/DVD 제품에 대해 2001/2002년도의 매출 실적을 보여준다.
다음은 스프레드시트 기능을 추가한 SQL의 확장 구문을 보여준다.
FROM table-list
WHERE conditions
GROUP BY grouping-column-list
HAVING having-condition
SPREADSHEET spreadsheet-clause
ORDER BY ordering-column-list
앞 SQL문의 논리적인 수행 순서는 WHERE->GROUP BY/HAVING->SELECT->SPREADSHEET->ORDER BY 순이다. 앞의 스프레드시트 절(spreadsheet-clause)은 좀더 자세히 다음과 같이 표현된다.
[SEQUENTIAL ORDERED]
[ITERATE (n) [UNTIL ( [UPSERT [UPSERT ..., [UPSERT )
앞에서 PBY(cols)는 select절까지 수행한 결과를 분할(partition by)하는데 사용되는 칼럼(들)을 지정하는 것이고, DBY(cols)는 분할된 파티션 내에서 분석 차원(dimension by) 역할을 담당하는 칼럼(들)을 지정하며, MEA(cols)는 분석 값(measure) 역할을 하는 칼럼(들)을 지정한다. 각각의 formula(공식)는 엑셀의 공식과 같은 의미를 지닌다. []으로 표시된 부분들은 나중에 차례로 설명하겠다. 다음 질의 1은 테이블 f를 대상으로 앞 스프레드시트 구문을 사용한 SQL의 예를 보이고 있다.
SELECT r, p, t, s FROM f SPREADSHEET PBY(r), DBY(p,t) MEA(s) ( UPSERT s[p='tv',t=2003] = s[p='tv', t=2002], UPSERT s[p='video',t=2003] = s[p='video', t=2001] + s[p='video', t=2002] )
질의 1의 의미는 ‘각 지역별로, 2003년도 TV의 매출은 2002년도 TV 매출과 같게, 그리고 2003년도 Video 매출은 2001년 Video 매출과 2002년 Video 매출과 같도록’ 데이터를 생성하는 것이다. 뒤에서 이 질의 수행의 결과를 보이겠다. 질의 1에서 각 공식은 일종의 치환문(assignment) 역할을 하는데, 왼편은 대상 셀(target cell)을 지정하고 오른쪽은 왼쪽 셀 값을 계산하는 데 사용되는 셀 또는 셀의 범위로 구성된다.
셀 참조
셀 참조(cell references)는 다음과 같이 차원 칼럼들의 값을 이용해 지정이 가능하다. 처음 셀 지정은 2002년도 TV의 매출액에 해당하는 셀을 지정하는 것이다. 다음 예는 제품명이 null 값인 경우를 지정하는 예를 보이고 있다.
s[p is null, t=2000]
각 차원 칼럼들에 대해 = 조건 이외에 >, >=, <, <= 등의 비교 연산자의 사용도 가능하다. 다음 공식에서 보여주듯이 공식의 오른편에 지정된 셀에 대해 함수 적용도 가능하다.
범위 참조
앞의 셀 지정은 특정한 하나의 셀만 지정하는 방법을 보여줬다. 공식의 오른쪽 수식에는 셀들에 대한 범위 참조(range references)도 가능하다. 다음의 오른쪽 식은 TV 제품에 대해 2001년부터 2002년까지 범위에 있는 매출 셀들을 지정하고 그 셀들을 대상으로 매출의 평균 값을 의미한다.
범위 참조된 셀들을 대상으로 사용 가능한 집단화 함수(aggregate function)는 avg 이외에 sum, max, min 등과 명시적인 순서를 요구하는 함수(예를 들어 참고자료 [이상원, SQL은 데이터분석에 적합한 언어인가?, 마이크로소프트웨어 2003년 1월호]의 분석 함수 중에서 윈도우(windowing) 기능을 사용하는 함수들)를 제외한 다양한 분석 함수들도 사용할 수 있다.
공식의 오른쪽 식뿐만 아니라 왼편의 셀도 범위 지정이 가능하다. 다음 예는 ‘2002년 이후의 각 제품의 매출은 그 전년도 해당 제품의 매출보다 20% 증가’시키는 스프레드시트 절을 보이고 있다.
(
s['west', *, t > 2002] = 1.2 * s[cv(r), cv(p), t = cv(t) 1]
)
앞에서 s[‘west’, *, t > 2002]의 * 표시는 제품(p) 차원의 모든 값을 표시하는데, west 지역의 2002년도 이후에 해당하는 모든 매출 셀들을 지정한다. 이 경우 공식의 오른편에 사용된 cv() 함수(currentv()의 단축형)는 공식 왼편의 현재 셀의 차원 값들을 지정하기 위해 사용된다. 주의할 점은 다음과 같은 경우 차원의 값에 따라 행들을 처리하는 수행 순서에 따라 다른 결과가 나올 것이다.
(
s['dvd', *, t <= 2002] = avg(s) ['dvd', cv(t) -2 <= t < cv(t)]
)
앞의 경우 2001년과 2002년 순서대로 처리한 결과와 반대로 처리한 결과는 다를 것이다. 이와 같은 경우는 SQL 질의 컴파일러가 검사해서 특정 순서대로 수행하도록 보장해 준다. 사용자가 명시적으로 순서를 지정하고자 하는 경우 다음과 같이 순서를 지정할 수 있다.
(
s['dvd', *, t <= 2002] ORDER BY t ASC = avg(s) ['dvd', cv(t) -2 <= t < cv(t)]
)
스프레드시트 기능의 획기적인 특징은 SQL문의 결과에 새로운 행을 생성할 수 있다는 점이다. 각 공식은 치환문의 역할을 하는데, 이때 의미는 디폴트로 UPSERT(해당 행이 없으면 INSERT하고 있는 경우에는 UPDATE)의 의미를 갖는다. 즉, 공식의 왼편에 해당하는 셀이 SQL의 결과에 없는 경우 그 셀에 해당하는 튜플을 생성하고, 있는 경우에는 해당 셀의 값을 갱신하게 된다. f 테이블을 대상으로 다음과 같은 질의를 수행하면 <표 2>와 같이 새로운 네 개의 튜플이 생성된다.
FROM f
SPREADSHEET PBY(r) DBY(p,t) MEA(s)// UPSERT가 default임
( // 다음 공식에서 명시하지 않아도 됨
UPSERT s['tv', 2003] = s ['tv', 2002],
UPSERT s['video', 2003] = avg(s) ['video', 2001<= t <= 2002],
)
<표 2>에서 보여지듯 새로운 네 개의 튜플이 생성되고 c처럼 명시적으로 사용자가 지정하지 않은 값은 NULL로 설정된다. 만일 사용자가 다음과 같이 UPDATE로 지정하게 되면 해당 셀이 존재하지 않는 경우는 그냥 무시하고 존재하는 경우에만 갱신하게 된다. 따라서 다음 예에서는 새로운 튜플이 생성되지 않는다.
FROM f
SPREADSHEET PBY(r) DBY(p,t) MEA(s)
(
UPDATE s['tv', 2003] = s ['tv', 2002],
UPDATE s['video', 2003] = avg(s) ['video', 2001<= t <= 2002],
)
참조 스프레드시트
분석 애플리케이션의 경우, 차원이 다른 분석 객체들의 조합을 통해 분석을 수행하는 경우가 있다. 예를 들어 f 테이블이 r, p, t차원을 갖고 있고 예산 분배 테이블 budget(r, p)은 지역에 해당하는 차원 r과 매출 증대 예상 비율 p를 가질 때 f 테이블을 대상으로 스프레드시트 기능을 이용하면서 budget에 정의된 스프레드시트를 참조할 필요가 있다. 이때 참조되는 스프레드시트를 참조 스프레드시트(reference spreadsheet)라 한다. 다음 예를 살펴보자.
FROM f
GROUP BY r, t
SPREADSHEET
REFERENCE budget ON (SELECT r, p FROM budget) DBY(r) MEA(p)
DBY(r,t) MEA(s)
(
s['west', 2003] = p['west'] * s['west', 2002],
s['east', 2003] = s['east', 2001] + s['east', 2002]
)
앞 예제는 west 지역의 2003년 매출 예상치를, budget에 정의된 참조 SPREADSHEET을 이용해 계산하는 것을 보여주고 있다. 참조 스프레드시트의 목적은 관계형 DB에서 조인과 유사한 기능을 수행한다.
공식 처리 순서
앞의 여러 예에서 본 것처럼 스프레드시트 절 안에는 하나 이상의 여러 개의 공식을 사용할 수 있고, 각각의 공식들은 공식의 정의가 서로 의존하는 경우가 있다. 이때 SQL 질의 컴파일러는 이들 간의 의존 관계(dependency)를 분석해 특정한 순서대로 공식들을 처리하게 된다. 이와 같은 방식을 자동 순서(automatic order) 방법이라 부른다. 예를 들어 다음 스프레드시트 절에서 F1은 F2에 의존한다. 즉, 공식 F1의 s[‘tv’, 2001] 셀의 값이 공식 F2의 정의에 따른다. 따라서 이 경우는 자동으로 F2가 먼저 처리돼야 한다.
(
F1: s['tv', 2003] = s ['tv', 2002] + s ['tv', 2001],
F2: s['tv', 2001] = 1000
)
어떤 경우에 사용자는 공식들이 나열된 순서대로 처리하기를 원할 수도 있는데, 이 때는 다음과 같이 명시적인 처리 옵션 SEQUENTIAL ORDER를 사용하면 된다. 이 경우 F1, F2의 순서대로 처리가 된다.
(
F1: s['tv', 2003] = s ['tv', 2002] + s ['tv', 2001],
F2: s['tv', 2001] = 1000
)
재귀적 공식 및 싸이클
엑셀에서 제공되는 기능과 유사하게 다음과 같은 재귀적 공식의 정의도 가능하다.
SELECT x, s FROM (SELECT 1 as x, 1024 as s FROM dual) SPREADSHEET DBY(x) MEA(s) ( s[1] = s[1]/2 )
앞의 경우 무한대로 s[1]의 값이 반씩 줄어들게 되므로 재귀적으로 앞 공식의 수행이 끝나는 조건을 명시할 수 있어야 한다. 이를 위해 다음과 같이 반복 회수와 재귀적 수행의 종료 조건을 명시할 수 있다.
(
s[1] = s[1]/2
)
ITERATE(10)은 재귀적 공식을 최대 10회까지 반복하게 되고, UNTIL (PREVIOUS(s[1]) s[1] < 1)은 재귀적 수행 과정에서 S[1]의 이전 값과 현재 값의 차이가 1이하가 되는 순간에 멈추게 된다. 예를 들어, s[1]의 값이 초기에 1024( = 210) 이상일 경우, 10회 반복 수행 후에 끝나게 되고, 1024 이하였을 경우에는 UNTIL의 조건이 만족되는 때 멈추게 된다.
다음은 스프레드시트 내에서 두 공식 F1, F2가 상호 의존 관계를 갖는 경우 즉 싸이클(cycle)을 형성하면 SQL 컴파일러가 이들의 수행 순서를 결정해(이 경우 F1, F2 순서대로 수행된다고 가정) 2회 반복 수행하는 예를 보여준다.
SELECT x, s FROM (SELECT 1 as x, 1 as s FROM dual UNION SELECT 2 as x, 2 as s FROM dual) SPREADSHEET DBY(x) MEA(s) ITERATE(2) ( F1: s[1] = s[2], F2: s[2] = 2 * s[1] )
이 SQL이 수행되면 결과로는 s[1] = 4, s[2] = 8이 된다.
스프레드시트와 ANSI 표준 SQL의 비교
우리는 대략적으로 SQL 스프레드시트의 본질적으로 확장된 표현력에 관해 알아봤다. 여기서는 지금까지 살펴본 확장된 SQL 스프레드시트 기능의 표현력과 기존 ANSI SQL을 이용해 이를 표현하는 방식에 비해 얼마나 효과적으로 계산을 할 수 있는지를 알아보자.
SELECT r, p, t, s FROM f SPREADSHEET PBY(r) DBY(p,t) MEA(s) ( F1: UPDATE s['tv', 2003] = slope(s,t) ['tv', 1991 <= t <= 2002] * s['tv', 2002] + s['tv',2002], F2: UPDATE s['video', 2003] = s['video',2001] + s['video',2002], F3: UPDATE s['dvd', 2003] = s['tv',2002] + s['video',2002] + s['dvd',2002] )
공식 F1을 ANSI SQL로 표현하기 위해서는 slope() 함수를 계산하기 위한 서브 질의(subquery)를 수행하고 이를 테이블 f와 조인을 수행해야 한다. 공식 F2의 경우 테이블 f에 대한 셀프조인(self-join)을 필요로 한다. 마지막으로 F3의 경우 f 테이블에 대해 셀프 조인을 두 번 수행해야 한다.
주목할 점은 각각의 공식 계산은 본질적으로 행 상호간 계산(inter-row calculations)이라는 점이다. 즉, 각각의 공식 계산은 공식 왼편의 셀의 새로운 값을 PBY에 의해 파티션되고, DBY에 의해 차원으로 구분된 행들로부터 왼쪽의 셀의 값을 계산하는 것이다. ANSI 조인의 경우 차원에 의해 서로 연관된 행들을 결합시키는 것은 반드시 조인을 유발시키게 된다. 예를 들어 질의 4의 마지막 공식 F3의 경우 다음과 같은 ANSI SQL 질의로 표현 가능하다.
SELECT r, p, t, s FROM f f1, f f2, f f3 WHERE f1.r = f2.r AND f1.r = f3.r AND f1.p = 'tv' AND f1.t = 2002 AND f2.p = 'video' AND f2.t = 2002 AND f3.p = 'dvid' AND f3.t = 2002
각각의 공식 F1, F2, F3에 해당하는 ANSI SQL 질의들을 결합(union)시키면 질의 4와 동일한 결과를 얻을 수 있다. 이 예에서 보여지듯 스프레드시트 기능을 이용하면 ① 복잡한 질의 표현을 간단하게 표현할 수 있고 ② 테이블 f에 대해 셀프조인이나 서브 질의의 수행 없이 결과를 얻을 수 있으므로 성능 면에서 유리하다. 특히 ANSI 조인으로 표현할 경우 하나의 공식은 거의 예외 없이 셀프 조인을 유발시키므로 공식의 개수가 늘어날수록 조인의 횟수도 늘어나 ANSI SQL로서 수행시킬 경우 성능은 참을 수 없을 정도로 느려진다. 반면 참고자료 [Andrew Witkowski et al., Spreadsheets in RDBMS for OLAP, Proceedings of SIGMOD, 2003]에서와 같은 수행 방법을 사용하게 되면 테이블 f에 대한 한번의 스캔(scan)과 약간의 특수한 자료 구조를 이용하여 처리가 가능하다. 따라서 관계형 데이터베이스에서 시간을 많이 소요하는 조인 연산을 회피하게 되므로 성능이 빨라지게 된다.
SQL 스프레드시트 기능 요약
우리는 이 글에서 SQL 스프레드시트 기능의 대략적인 특징에 대해 살펴봤다. 핵심적인 내용을 정리하면 다음과 같다.
◆ 공식(formula) : 엑셀과 같은 스프레드시트의 공식과 표현력에서 동일한 공식 기능 지원. 구체적으로 단일 셀 또는 셀의 범위에 대해 다양한 함수들을 적용해 계산을 수행한다.
◆ 행 상호간 계산(inter-row calculations) : 하나의 공식은 특정 파티션 내에서 서로 연관이 있는 행들간 계산을 통해 새로운 값을 도출한다.
◆ 자동적인 공식 처리 순서(automatic formula evaluation ordering) : 하나의 SQL 스프레드시트 내에 여러 개의 공식이 정의되고 이들 간에 의존 관계가 있는 경우 자동으로 공식간의 처리 순서를 결정한다.
◆ 재귀적인 계산 모델(recursive computation model) 지원 : 재귀적인 공식을 반복과 조건 기능을 이용해 유한하게 적용하는 계산 모델을 지원한다.
이상의 특징은 한마디로 요약하면, SQL 스프레드시트 기능은 엑셀과 같은 스프레드시트 도구에서 제공하는 ‘배열 기반의 복잡한 계산 모델’을 관계형 DBMS 내에서 직접 사용 가능하도록 해주는 것이다. SQL 스프레드시트 기능을 이용하게 되면 현재의 엑셀과 같은 스프레드시트 도구들에 비해 다음과 같은 중요한 몇 가지의 기술적인 장점이 제공된다.
◆ 데이터베이스 내에 스프레드시트 저장 : 사용자가 자신의 스프레드시트를 정의한 후 이를 저장하게 되면 이를 데이터베이스 내에 실체화된 뷰(materialized view) 형태로 저장한다.
◆ 자동적인 스프레드시트 내용 갱신(automatic spreadsheet refresh) : 실체화된 뷰 형태로 저장하게 되면 원래 소스 데이터 내용이 갱신될 경우 DBMS에 의해 스프레드시트의 내용도 자동으로 변경된다. 반면 스프레드시트 도구에서는 매번 새로이 데이터베이스에서 데이터를 옮겨와서 공식을 적용해야 한다.
◆ 스프레드시트간 통합 분석 : 결국 스프레드시트가 테이블로 저장되기 때문에 스프레드시트간 조인 연산을 통해 통합 분석이 가능하다. 엑셀과 같은 도구에서 스프레드시트간의 통합 분석 기능은 필자가 아는 한 제공되지 않는다.
◆ 스프레드시트에 대한 유연한 보안 기능(security) : 실체화된 뷰 형태로 저장되는 스프레드시트는 관계형 DBMS 입장에서는 하나의 테이블로 취급되기 때문에 관계형 DBMS가 제공하는 다양한 보안 기능을 스프레드시트에도 똑같이 적용할 수 있다.
비즈니스 데이터 분석가들 곁으로
이 글에서 살펴본 SQL 스프레드시트 기능은 이전에 SQL에 도입된 분석 함수 등과 더불어 관계형 DBMS를 진정한 분석용 플랫폼으로 진화시켰다는 점이다. 즉, 관계형 DBMS가 기존의 ROLAP, MOLAP, 엑셀과 같은 분석 도구들에 비해 가지는 단점-분석과 관련한 SQL 언어의 표현력(expressive power)의 한계-가 극복되었다는 점이다. 관계형 DBMS는 이들 도구들에 비해 갖는 가장 큰 장점 중의 하나가 대용량의 데이터를 처리할 수 있는 확장성(scalability)이다. 따라서 앞으로의 분석 도구들은 대부분 사용자 인터페이스와 관리 도구 기능들만 갖게 되고 데이터와 분석 기능들은 관계형 DBMS에서 제공되는 기능들을 십분 활용하게 될 것이다.
이러한 분석 기능들이 점점 더 SQL에서 제공되는 것은 데이터베이스 관련 국산 IT업체들에게 사업 기회를 제공한다고 판단된다. 예를 들어, 국산 넥셀과 같은 스프레드시트 도구에서 관계형 DBMS의 SQL 스프레드시트 기능을 활용하고 인터페이스만 제공하게 되면 엔터프라이즈 데이터를 대상으로 직접 스프레드시트의 분석 기능을 적용할 수 있다. 일반 사용자들은 몰라도 엔터프라이즈 데이터를 분석하는 사람들에게는 아주 매력적인 도구가 될 것이며, 결국 훨씬 고부가가치의 도구가 될 것이다.@





