



“기업 내 비즈니스 담당자가 데이터 분석작업을 하려는데 80%의 시간과 노력을 데이터 전처리에 쓰고 있다. 통찰력을 도출하거나 분석하는데 80%를 쓰는 게 아니다. 대부분의 전처리 과정이 IT전문가의 작업을 요구하기 때문이다.”
프라카시 난두리 팍사타 공동창업자 겸 CEO는 24일 기자간담회에서 이같이 말했다. 데이터 프렙이란 생소한 용어를 설명하면서 한 말이다.
팍사타(Paxata)는 기업 내외부의 정제되지 않은 대용량 데이터를 데이터 사이언티스트나 IT지식없는 일반사용자도 손쉽게 수집, 가공해 정보를 찾을 수 있도록 해주는 솔루션을 제공한다.
팍사타는 이같은 솔루션을 ‘데이터프렙’이란 분야에 속한다고 설명하는데, ‘Data Preparation’을 줄여서 부른 말이다.

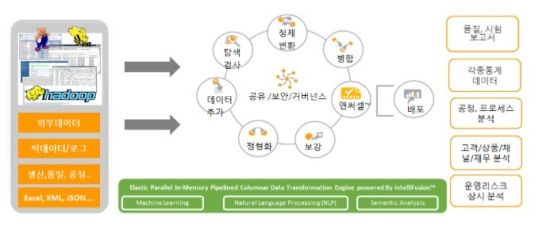
기업이 데이터를 분석하려면 우선 내외부의 데이터를 수집하고, 일목요연하게 정리한 뒤, 언제든 꺼내볼 수 있도록 잘 저장해야 한다. 빠르고 복잡한 분석을 위해 강력한 시스템도 구축해둬야 한다. 추출-변환-적재(ETL), 데이터통합, 품질관리, 거버넌스 등의 절차를 거쳐야 비로소 현업에서 분석할 수 있는 밑준비를 다 한 것이다. 이는 데이터 전처리라 불린다.
이같은 일련의 데이터 전처리 작업은 IT전문가의 몫이다. IT지식을 갖지 않은 분석가는 모든 준비가 끝날 때까지 기다려야 한다. 데이터프렙은 분석가에게 잘 정리된 데이터세트를 제공하는 작업을 자동화한 것을 가리킨다.
프라카시 난두리 CEO는 “데이터 분석 프로세스가 잘 안 되는 또 다른 이유는 IT와 비즈니스 부서의 상호 이해 부족”이라며 “IT부서는 데이터 가공이나 전처리 시 현업에서 필요로 하는 맥락을 잘 이해할 수 없고, 현업은 IT부서에서 쓰는 데이터 관련 툴을 잘 모른다”고 설명했다.
그는 “전통적 데이터 처리 환경을 가진 기업의 CEO는 특별한 고객이 몇명인가란 단순한 질문조차 바로 답을 받을 수 없다”며 “현업 분석가나 데이터 수집가가 수일, 수개월에 걸쳐 데이터를 준비한 후에야 답을 얻을 수 있다”고 덧붙였다.
팍사타는 데이터 전처리 자동화를 위해 머신러닝 기반 인공지능 알고리즘을 활용한다. 관리형-비관리형 알고리즘, 시맨틱 텍스트 알고리즘, 자연어 처리 알고리즘, 연산알고리즘 등 네가지 알고리즘이 제각각인 데이터들을 현업에서 요구하는대로 가공해준다. 현업 담당자는 자신의 업무지식으로 시스템을 학습시킴으로써 전처리 작업의 만족도를 높일 수 있다.
팍사타 시스템은 확장성 있는 분산컴퓨팅 환경을 기반으로 한다. 하둡과 아파치 스파크 인메모리 시스템을 통해 확장성과 빠른 연산속도를 확보했다.
IT적 지식을 갖지 못한 사람도 쉽게 분석에 돌입할 수 있도록 고객경험(CX)에도 신경썼다. 탄력적으로 사용할 수 있도록 퍼블릭, 프라이빗, 하이브리드 클라우드 컴퓨팅 환경에 구축된다.
난두리 CEO는 “과거의 툴과 기술은 주로 80만명의 데이터 개발자나 데이터 과학자를 대상으로 만들어졌다”며 “팍사타는 현재 10억명으로 추산되는 지식근로자를 중점에 두고 솔루션을 만들었다”고 강조했다.
그는 “어떤 특정 기술을 갖지 않은 지식 근로자가 로데이터를 정보로 만드는데, 몇달 몇주를 기다리지 않고 즉각 만들어 낼 수 있게 하자는 게 우리의 비전”이라고 덧붙였다.
관련기사
- "2019년 세계 빅데이터시장 규모 222조원"2016.05.24
- 제4차 산업혁명 시동건다…‘IoT-빅데이터 등 규제 철폐’2016.05.24
- 삼성이 데이터로 생산성을 높이는 방법2016.05.24
- 매스웍스 “엔지니어링 주도 분석이 뜬다”2016.05.24
잘레시아(대표 이상준)는 팍사타와 파트너십을 맺고 한국 시장에 공급한다. 잘레시아는 파트너십 체결을 통해 한국을 포함한 아태 지역(APAC)에 팍사타를 공급하게 된다.
팍사타코리아 이혁구 지사장은 “많은 기업이 기존 데이터 공급망의 재구축 없이, 쉽고 빠르게 빅데이터 등의 대용량 데이터 분석 이슈를 해결해 줄 솔루션을 원한다”며 “팍사타는 이러한 시장의 요구사항을 정확히 만족시키는 업계 유일의 엔터프라이즈급 솔루션”이라고 말했다.





