






대표적인 빅데이터 분석 플랫폼인 스플렁크 보다 더 빠르면서 쓰기 쉬운 DB엔진을 개발해 공급하겠다는 것을 비전으로 가진 국내 업체가 있다.
DB 분야 개발 경력만 16년이 넘는 김성진 대표, 심광훈 본부장, 이재훈 본부장이 의기투합해 만든 인피니플럭스다. 2013년 설립돼 만 3년이 지난 이 회사는 국산 DB를 개발했지만 애초부터 글로벌 시장 진출을 겨냥했다고 말한다. 그들은 뭐가 다르길래 스플렁크 보다 뛰어난 성능을 낼 수 있다고 자신하는 것일까?
최근 DB업계에선 인메모리 기반 기술이 주목을 끌고 있다. 인메모리DB는 메모리에 데이터를 저장하는 방법으로 이전 방식보다 인덱싱(색인)이나 검색 속도를 높였다.
문제는 이러한 방식이 하루 평균 수백 GB에서 수 TB에 달하는 빅데이터 수준의 대용량 데이터를 처리하기에는 용량이 부족하다는 한계가 지적되고 있다는 점이다.
때문에 각종 장비에서 나오는 로그데이터와 함께 사물인터넷(IoT) 시대를 맞아 폭증할 것으로 예상되는 센서데이터를 포함하는 일명 '머신데이터'를 다루기 위해 등장한 것이 스플렁크가 제공하고 있는 디스크 기반 검색엔진이다.
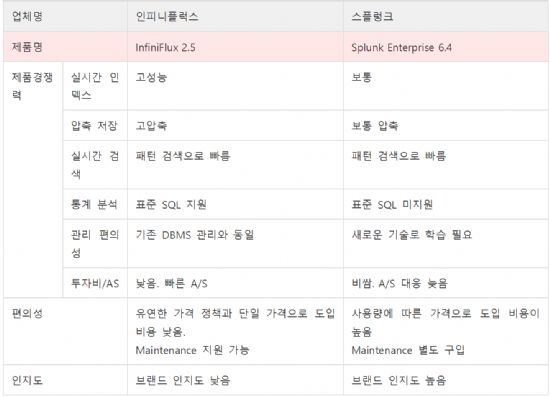
그러나 현업부서에서 실무를 맡고 있는 담당자 입장에서 스플렁크가 제공하는 검색엔진을 다루기가 쉬운 것은 아니다. 인피니플럭스 관계자에 따르면 검색을 위해 과거 DB에 가장 널리 사용됐던 표준 SQL 구문을 지원하지 않는 탓이다. 스플렁크는 SPL이라는 자체 구문을 통해 검색 기능을 제공하고 있다. 기존 DB개발자들이 새로운 언어를 배워야한다는 부담이 생기는 것이다.
인피니플럭스는 이러한 어려움을 해결하기 위해 스플렁크처럼 빅데이터 수준의 대용량 데이터를 저장하면서도 오라클RDB, 마이SQL 등 인메모리 DB가 지원하는 표준 SQL 구문을 쓸 수 있게 했다. 메모리 대신 디스크를 쓰되 컬럼형 DB를 구성하는 방식으로 인덱싱과 검색 속도는 대폭 높였다는 설명이다.
이 회사는 자사 인피니플럭스 2.0, 마이SQL 5.2, 스플렁크 6.2.3, 엘라스틱서치 1.5.3, 몽고 3.0.3에 대해 같은 하드웨어 조건에서 1억건(13GB)에 달하는 데이터 입력, 분석 성능을 측정했다.
그 결과 인피니플럭스 제품군은 1억건 데이터를 입력하는데 393초가 걸렸다. 스플렁크가 698초로 2위였고, 마이SQL이 1만3천848초로 가장 오랜 시간이 들었다.
복합 연산 조건으로 검색을 수행해 본 결과, 마이SQL이 1초로 가장 빨랐으며 엘라스틱서치(3초), 인피니플럭스(4초) 순으로 나타났다. 스플렁크의 경우 85초다. 이 회사 측은 검색 속도는 마이SQL이 빨랐지만 데이터를 입력하는 시간이 걸린다.
전체 데이터 입력, 복합 연산 조건으로 검색에 걸리는 시간을 합치면 인피니플럭스 2.0이 394초로 가장 적은 시간이 든다는 설명이다. 스플렁크는 783초가 걸렸다.
이 회사는 13GB의 원본데이터를 인덱스 정보를 포함해 압축저장할 경우 4.1GB 저장용량이 필요했다. 스플렁크는 21.6GB가 들었다.
인피니플럭스 DB엔진은 표준 SQL 외에도 'Duration', 'Search'라는 구문을 제공해 초 단위로 검색과 분석을 수행할 수 있으며, 통계 추이를 분석할 수 있는 'Result Cache'라는 구문을 개발했다.
관련기사
- "빅데이터 보안 역량, 다양한 관점의 분석에 달렸다"2016.05.16
- 보안에 최적화된 국산 DB 등장...위협 대응 속도↑2016.05.16
- 스플렁크, 머신러닝 기반 보안 스타트업 인수2016.05.16
- 오라클, 스플렁크 인수 가능성 솔솔...왜?2016.05.16
이들이 보유한 기술은 실시간 로그데이터를 빠르게 분석해 처리해야하는 네트워크 보안 장비에 도입되면서 성능을 검증했다. 현재 시큐아이, 퓨처시스템 등에 자사 DB엔진을 공급하는 중이다.
이 회사는 글로벌 시장을 노려 기술을 개발한 만큼 이미 한국 뿐만 아니라 미국, 일본에도 글로벌 오퍼레이션 사무소를 열었다. 이를 통해 디스크 기반 컬럼형 DB를 제공하는 회사로 지난해 시스코에 인수된 파스트림과 같은 회사들과 직접 경쟁에 나서겠다는 포부다.





