






페이스북이 하둡을 위한 SQL처리엔진 '프레스토'를 마침내 오픈소스SW로 공개했다. 아파치 하이브보다 10배 빠르다는 설명이다.
6일(현지시간) 외신에 따르면, 페이스북은 대화형 SQL온하둡 엔진 '프레스토(Presto)'를 공개했다.
프레스토는 하둡분산파일시스템(HDFS) 내 저장된 데이터를 맵리듀스 엔진을 이용하지 않고 SQL언어로 빠르게 조회, 분석할 수 있게 해주는 기술이다. 커맨드라인인터페이스(CLI)에서 SQL 질의를 던지도록 했다.
일반적으로 하둡 속 데이터를 SQL로 조회하는 방법은 하이브를 사용하는 것이다. 하이브는 유사 ANSI SQL쿼리를 사용할 수 있어 기존 분석가가 쉽게 사용할 수 있다는 장점을 갖지만, 대용량병렬처리(MPP) 기반 DW 시스템보다 쿼리 처리시간에서 뒤진다. 하이브가 SQL 쿼리를 맵리듀스 잡으로 전환하는 과정이 중간에 추가되기 때문이다.
하이브의 한계를 뛰어넘어 SQL조회를 빠르게 할 수 있는 기술이 'SQL온하둡'이란 흐름이다. 하둡 진영에서 대거 개발되고 있다. 클라우데라의 임팔라(Impala), 그루터 주도로 개발되는 '아파치 타조'도 그 일종이다.
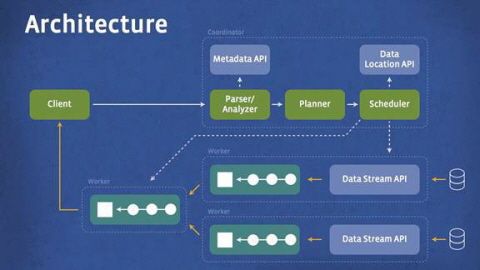
프레스토는 맵리듀스 프로그래밍에 문외한인 데이터 분석가가 기존 SQL언어로 대용량의 데이터를 대화하듯 분석할 수 있게 해준다.
페이스북은 프레스토를 지난해 가을부터 데이터인프라스트럭처그룹에 소규모 조직을 꾸려 개발하기 시작했다. 사용자 분석용 데이터를 저장하는 페이스북 하둡 클러스터의 300페타바이트 데이터를 효율적으로 분석하려는 용도였다. 특히 지금보다 데이터 규모가 기하급수적으로 늘어나고 있어 현재 인프라 기술로는 대화형 쿼리 시스템이 한계에 봉착할 것이란 판단도 있었다.
프레스토는 자바로 만들어졌으며, 메모리 처리와 데이터 구조 기술을 적절히 혼합해 자바 코드의 메모리 할당과 쓰레기 정보 수집 문제를 피한다.
프레스토의 또다른 특징은 확장성이다. HDFS와 HBASE 같은 데이터저장소 외에 뉴스피드 백엔드 속 스토리지와 쉽게 연결되도록 했다. 메타데이터 API와 데이터로케이션API를 통해 데이터가 어디있든 쉽게 연결할 수 있다.
현재 페이스북은 프레스토를 여러 지역에서 운영중이고, 1천개 노드로 구성된 단일 클러스터가 성공적으로 운영되고 있다. 이 시스템에 수천명의 페이스북 직원이 하루당 1페타바이트 처리를 유도하는 3만개 이상의 쿼리를 던지고 있다.
관련기사
- SK텔레콤 오픈소스SW 투자의 의미2013.11.07
- 빅데이터, 기업시장 열어줄 열쇠는?2013.11.07
- 페이스북, 250페타급 DW 조회엔진 공개2013.11.07
- IBM, 'SQL 온 하둡' 참전…의미는2013.11.07
페이스북은 향후 조인 작업을 개선하고, 쿼리 처리에 최적화된 데이터 포맷도 새로 개발할 것이라고 밝혔다.
프레스토는 아파치2.0 라이선스를 따른다.





