





데이터 통신과 네트워크 디자인을 희망하는 사람이라면 누구나 알아야 하는 테크닉이 바로 큐잉 이론입니다. 전산학을 비롯한 거의 모든 컴퓨터 네트워크와 통신 분야의 디자이너들에게 큐잉은 시스템의 행동 특성을 빠르게 분석, 설계, 그리고 평가할 수 있게 해주는 주요한 툴로 사용되고 있습니다.
이번 연재에서는 이러한 큐잉을 대기와 처리의 관점에서 네트워크에 어떻게 적용되는지 설명하고 두 가지 예제를 함께 풀어보겠습니다.
노드와 링크의 조합인 네트워크에는 데이터의 트래픽 조절과 혼잡 제어가 필요합니다. 트래픽 조절이란 고속도로에서의 교통상황처럼 데이터 송신 노드(source node)에서 목적 노드(destination node/sink node)로 데이터가 전송될 때 목적 노드 쪽에서 데이터를 너무 빠르게 처리하거나(자원 낭비) 너무 느리게 처리(낮은 효율)하지 않도록 하는 것을 말합니다.
혼잡 제어는 2개 이상의 노드로부터 링크를 통해 데이터를 전송할 때 데이터 충돌을 피하거나 해결하기 위한 방법입니다. 이상의 방법들은 높은 데이터 전송 효율을 목표로 하는 네트워크엔 꼭 필요한 요소이며 네트워크 디자이너들은 이러한 트래픽 관리를 통해 현 상태와 앞으로의 네트워크 상태를 가늠할 수 있어야 합니다.
이와 같은 데이터 통신과 네트워크 디자인을 희망하는 사람이라면 누구나 알아야 하는 테크닉이 바로 큐잉 이론(Queuing Theory)입니다. 독자들은 아마도 큐(queue)라는 용어를 자료구조 관련 서적에서 대기 행렬이라는 용어로 접해보았을 것입니다.
다시 이해를 돕자면 큐는 먼저 들어온 데이터가 먼저 처리되는(First In First Out) 데이터의 저장 형태라고 할 수 있습니다. 이러한 것은 큐잉의 기본 개념에 불과합니다. 전산학을 비롯한 거의 모든 컴퓨터 네트워크와 통신 분야의 디자이너들에게 큐잉은 시스템의 행동 특성을 빠르게 분석, 설계, 그리고 평가할 수 있게 해주는 주요한 툴로 사용되고 있습니다. 이번 글에서는 이러한 큐잉을 대기(queue)와 처리(serve)의 관점에서 네트워크에 어떻게 적용되는지 설명하고 예제를 풀어 봄으로써 독자 여러분의 이해를 돕겠습니다.
얼마 전에 다이수케 테라사와의 ‘초밥왕’이라는 만화를 보았습니다. 주인공 세키구치 쇼타가 초일류 초밥을 준비하기 위하여 재료들을 배우고 준비하는 마음가짐을 보고 기본기의 중요성을 다시 한번 마음에 되새기는 계기가 되었습니다. 큐잉 이론과 네트워크 모델링에 관한 이야기를 하기에 앞서 독자들이 이미 알고 있을 내용이겠지만 잠시 확률에 관한 기본기를 살펴보며 확률에 대한 기억을 되새겨 보겠습니다.
확률 되돌아보기
세 개의 빨간 구슬과 두 개의 파란 구슬이 담겨있는 항아리에서 빨간 구슬을 뽑을 사건을 시행할 때 사건의 결과가 목적을 만족시킬 확률을 묻던 산수책의 문제 기억납니까? 아마 대부분의 독자들은 이러한 문제들을 초등학교 때부터 지금까지 서적과 수업, 생활 속에서 많이 접해 보았으리라 생각합니다.
확률은 17세기 파스칼과 페르마라는 수학자간의 도박에 관한 이야기 속에서 학문적으로 체계화되었다고 합니다. 또한 확률은 복잡한 통계적 계산에 대한 정확한 처리라는 컴퓨터 발전의 기본 목표이기도 하였습니다. 이러한 확률은 네트워크의 기본 설계에 녹아 있습니다.
예를 들면 대개의 디자이너들이 데이터 전송과 수신시의 성공과 실패를 확률로 구분하고 디자인의 제한 조건으로 둡니다. 여러분이 사용하고 있는 모든 네트워크 장치들은 이러한 것들을 모두 만족시켜 준 것들이라고 할 수 있습니다. 이렇게 네트워크 속에서 확률의 예를 찾자면 몇 권의 책, 며칠의 시간으로도 아마 모자랄 것입니다.
확률의 기본 정의
공명(axioms)이라는 것은 수학에서 무증명 명제(無證明 命題)라고 불리는 것으로, 기초를 세우기 위해 받아들이는 수학적 단정(assertion)이라고 할 수 있습니다. 일단 이러한 공명이 받아들여지면 우리는 법칙을 증명할 수 있는 것입니다.
어떠한 사건 Ω는 각각의 실험에서 발생한 사건의 모든 집합을 말하며 표본 공간(Sample Space, 그래서 S로 나타내기도 하지요)라고 합니다. 합집합 A∪B(A union B)는 사건 A와 B가 각각 혹은 동시에 일어날 수 있는 모든 사건의 집합을 말합니다. A∩B(A intersection B)는 사건 A와 B가 동시에 일어나는 사건을 말합니다. 만약에 A∩B={}라고 하면 A와 B는 동시에 일어나는 사건이 없어 서로 배반 관계(mutually exclusive)라고 합니다.
확률은 어떤 사건이 일어나는 확실성의 정도를 수량적으로 나타낸 것입니다. 주사위의 예를 들면 주사위를 던진 후 하늘을 향하는 숫자를 하나의 사건이라고 한다면 모두 6개의 사건이 일어날 수 있습니다. 주사위가 균등하게 모든 이벤트를 발생한다고 가정하면 3보다 작거나 짝수인 사건(1, 2, 4, 6)이 나올 확률은 Pr[{짝수}∪{3보다 작은 수}] = Pr[짝수] + Pr[3보다 작은 수] - Pr[{짝수}∩{3보다 작은 수}] = 1/2 + 1/3 - 1/6 = 2/3가 될 것입니다. 다음과 같이 확률의 공명을 정리해 보았습니다.
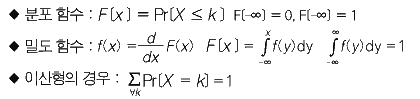
확률 변수
확률 변수(random variable)는 쉽게 설명하면 확률을 나타내는 변수를 말합니다. 다시 말해서 표본 공간에서 일어나게 될 모든 이벤트들을 숫자로 나타내는 것입니다. 예를 들면 동전을 세 번 던져서 순서에 상관없이 앞면이 한번이라도 나올 확률은 Pr{뒤,뒤,뒤}=1/8을 제외한 Pr{앞,뒤,뒤}= 3/8, Pr{앞,앞,뒤}=3/8, Pr{앞,앞,앞}=1/8입니다. 여기서 우리가 다시 앞면이 나온 횟수를 X로 나타내면 Pr{X=0}=1/8, Pr{X=1}=3/8, Pr{X=2}=3/8, Pr{X=3}=1/8로 나타낼 수 있습니다.
확률 변수 X는 다음과 같이 밀도 함수(density function)와 분포 함수(distribution function)에 사용될 수 있습니다. 특히 확률 변수가 셀 수 없는 무한한 값에 대해서는 연속적(continuous)이라고 하며 반대의 경우에는 이산형(discrete)이라고 부릅니다.
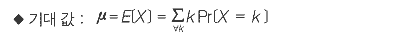
분포 함수란 일어날 사건의 범위에 대한 확률의 분포를 나타낸 것입니다. 반면 밀도 함수는 이러한 분포 함수를 나타낼 수 있는 함수를 정의하며 밀도 함수를 앞의 식과 같이 모든 범위에 대하여 적분을 하면 1이 됩니다.
기대 값(expected value)이란 확률 변수 X를 사용하여 가 확률 현상의 결과가 수 값으로 나타날 경우 사건 시행의 결과로 기대되는 수 값의 크기를 말합니다. 예를 들면 10번의 데이터 통신을 하여 3번의 에러가 나는 네트워크에서 5번의 통신을 하면 몇 번의 에러가 발생하는가에 대한 기대 값 혹은 평균 값이라고 할 수 있습니다. 이러한 기대 값은 E[X] 혹은 μ(뮤)로 나타냅니다.

포아송 분포
확률 통계에는 정규 분포, 이항 분포, 지수 분포 등과 같이 다양한 분포가 있습니다. 이 중 포아송 분포(Poisson Distribution)는 발생 확률이 작은 사건을 대량적으로 확대하여 그 발생 횟수가 만드는 분포를 확률적으로 정의한 것을 말합니다.
포아송 분포는 전화통화 시간, 전화통신 성공 횟수, 텔넷과 ftp 세션의 연결 등을 예상하여 디자인에 사용하기 적합한 분포입니다. 또한 이번 연재의 주제인 큐잉 이론에 가장 쉽게 사용되는 분포이기도 합니다. <그림 1>은 대표적인 포아송 분포의 그래프입니다. λ는 패킷이 도착하는 비율을 나타내며 다음의 식과 같은 분포 함수를 가지고 있습니다.
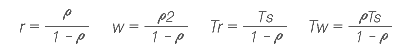

네트워크 모델링에서 큐잉 이론
잠시 여러분이 2명의 주문 담당 직원이 있는 패스트푸드 음식점의 사장이라고 가정하겠습니다. 여러분의 음식점에는 오전 11시부터 오후 1시 30분까지는 평상시 2배의 손님이 들어와 주문을 하기까지 평균 15분의 대기 시간을 가져야 합니다. 이 문제를 해결하기 위해서 무엇을 가장 먼저 생각하겠습니까?
우선 고객이 기다려야 하는 15분이라는 문제를 해결해야 겠지요. 그럼 몇 명의 주문담당 직원을 추가적으로 배치해야 효과를 얻을 수 있을까요? 2명? 3명? 이러한 문제에 대한 해답을 주는 것이 큐잉 이론입니다. 앞서 언급한 것처럼 큐잉 이론은 비단 컴퓨터 모델링뿐만 아니라 수많은 산업에서 모델링에 사용되고 있는 툴입니다. 네트워크에서는 데이터를 고객으로 생각하고 주문 담당을 서버로 생각하여 효율적인 디자인을 하는 데 많이 사용되고 있습니다. 큐잉 이론에 기저하여 디자인한 분석적 모델을 프로그래밍하고 실행한다면 아주 훌륭한 네트워크 시뮬레이션 모델이 될 것입니다.
큐잉 모델

<그림 2>는 가장 간단한 큐잉 모델입니다. λ는 큐잉 시스템에 도착하는 패킷의 도착 시간의 비율(패킷/sec)입니다. 예를 들면 라우터에 도착하는 패킷이나 전화 교환기에 도착하는 전화, 그리고 독자들의 패스트푸드 가게에 도착하는 손님들의 시간 비율이 될 것입니다. 만약 어떤 특정한 시간에 패킷이 도착했을 때 대기열에서 서비스를 기다리고 있는 패킷이 없다면 그 손님은 줄을 서지 않고 서비스를 받을 것입니다.
w는 대기열에서 서비스를 기다리고 있는 패킷의 평균 개수입니다. Tw는 대기열에서 기다려야 하는 평균 시간입니다. 여기서 평균이라 함은 패킷이 기다리지 않는 시간까지 함께 포함합니다. Ts는 서버가 패킷에게 서비스를 제공하는 시간을 말합니다.
ρ(로)는 서비스 유틸라이제이션(utilization)입니다. 이것은 서버가 일을 하고 있는 비율입니다. 예를 들어 서버 유틸라이제이션이 1인 경우는 서버가 100% 일을 하고 있다는 의미로 도착한 패킷들은 서버에서 서비스를 제공받을 수 없으며 큐에서 대기해야 합니다.
이러한 경우 디자이너들은 두 가지 선택을 할 수 있습니다. 대기열을 늘리거나 서버를 증설하거나 말이죠(들어오는 손님을 막을 수는 없겠죠?) 대기열을 늘리면 대기열에 들어오지 못하던 패킷들을 기다리게 할 수는 있지만 여전히 기다리는 패킷들의 불평은 해결할 수 없을 것입니다.
서버를 증설한다면 좀 더 원활한 서비스를 제공할 수 있겠지만 기존의 서버 유틸라이제이션이 낮아지면 전체적인 시스템 측면에서 낮은 효율의 원인이 될 수 있을 것입니다. 이러한 점이 엔지니어들이 디자인할 때 항상 고려해야 하는 트레이드 오프(trade-off)라는 것입니다.
독자들의 서버가 100%(ρ=1)로 일을 하고 있다면 큐잉 시스템을 나가는 패킷의 시간 비율은 도착하는 패킷의 시간 비율과 상관없이 항상 일정할 것입니다. 이러한 제한적 환경에서 시스템이 최대로 해결할 수 있는 도착하는 패킷의 시간 비율은 이론적으로 다음과 같이 나타낼 수 있습니다.
하나의 패킷, m이 도착했다고 가정합니다. m의 앞에는 평균적으로 w개의 패킷이 대기열에서 서비스를 받을 순서를 기다리고 있을 것입니다. m이 대기열을 떠나 서비스를 받으러 가면 대기열에는 다시 w개의 패킷이 기다리고 있을 것입니다.
그리고 Tw는 평균 대기 시간이 됩니다. 그렇기 때문에 λ의 비율로 도착한 패킷을 이용하면 w=λTw라는 것을 알 수 있습니다. 비슷한 방법으로 우리는 r=λTr임을 알 수 있습니다. 이것이 바로 리틀의 이론(Little's Formula)입니다. 리틀의 이론을 좀 더 응용하면 ρ=λTs, r=w+ρ을 구해 낼 수 있습니다.
독자들의 상사는 하나 혹은 둘의 제한(패킷 서비스 비율이나 서버 유틸라이제이션)을 주고 네트워크를 디자인하기를 원하고 있습니다. 어떻게 디자인하겠습니까? 자 그럼 이제 가장 효율적인 네트워크 디자인을 위한 연장(tool)을 다시 챙겨보도록 하겠습니다. 일반적인 큐잉 시스템에서 디자이너들에게 다음과 같은 입력(input)이 주어집니다.
[1] 도착 비율(패킷/sec)
[2] 서비스 타임
[3] 서버의 개수
그리고 다음의 결과를 요구합니다.
[1] 대기열 속의 패킷 개수
[2] 대기하는 패킷의 시간
[3] 큐 시스템 전체의 패킷 개수
[4] 전체 시간
가장 중요한 가정은 도착하는 패킷의 비율(arrival packet rate)에 관한 것입니다. 대개의 경우 성공적으로 도착하는 패킷과 패킷 사이의 시간(inter-arrival times)을 exponential하다고 가정하는데 이것은 패킷의 도착 비율 λ가 포아송 분포를 따른다는 말입니다. 이해를 돕자면 패킷이 무작위로 독립적(Independent)으로 도착한다는 말입니다.
또한 서비스 시간은 exponential하다고 합니다. 이러한 가정을 간단하게 켄돌(Kendall)의 표기법을 따서 M/M/1(엠엠원)이라고 합니다(1은 서버의 개수). M/M/1의 경우는 가장 간단한 큐잉 모델이라고 할 수 있습니다. 다음은 이러한 경우의 파라미터에 대한 대응 공식을 나타내고 있습니다.
그럼 실제 예제를 통해 큐잉 이론을 네트워크에 적용해 보도록 하겠습니다.
<예제 1>
여러분이 디자인하게 될 랜은 100명의 사용자가 연결될 것입니다. 그리고 한 개의 서버를 사용해야 합니다. 사용자의 요청에 따른 서버의 평균 서비스 타임은 0.6초입니다. 피크 타임에는 1분에 20명의 사용자가 사용 요청을 할 것입니다. 평균 대응 시간은 얼마입니까?
<풀이 1>
우선 큐잉 모델을 M/M/1로 가정합니다. 그리고 랜 상황에서 일어나는 지연(delay)은 충분히 무시할 만한 수준이라고 가정하고 디자인합니다. 예제로부터 Ts=0.6임을 알아냅니다.
<풀이 1>을 통해서 서버 요청에 따른 평균 응대 시간이 0.75초임을 알게 되었습니다.
<예제 2>
독자의 상사가 다음의 질문을 물어 보았다고 가정합니다. 다른 네트워크로 연결된 랜으로 패킷들이 보내어지고 있습니다. 모든 패킷들은 랜에 연결된 라우터를 지나서 네트워크로 보내져야만 합니다.
패킷들은 평균 5/sec으로 라우터에 도착합니다. 그리고 평균 패킷의 길이는 144옥텟(octets)이며 패킷 길이는 지수 분포를 따릅니다. 라우터로부터 네트워크까지의 라인 스피드는 9600bps입니다. 라우터에 도착한 패킷이 처리되어 나갈 때까지의 평균 시간은 얼마입니까? 또한 대기열에 있는 패킷을 포함하여 얼마나 많은 패킷이 평균적으로 라우터에 머물게 됩니까?
<풀이 2>
큐잉 모델은 M/M/1이기 때문에 우리는 공식을 사용할 수가 있습니다. 문제로부터 우리는 λ=5패킷/sec임을 알고 있습니다.
<풀이 2>를 통해서 우리는 라우터 안에 평균적으로 1.5개의 패킷이 있으며 도착해서 서비스를 받고 라우터를 나가는 평균 시간이 0.3초임을 알 수 있었습니다.
다음엔 NS-NAM을 이용한 시뮬레이션
지금까지 큐잉 이론을 이용하여 간단한 네트워크를 수학적으로 모델링을 해보았습니다. 다음에는 ‘NS-NAM으로 해보는 네트워크 디자인 소프트웨어 시뮬레이션’이란 제목으로 NS-NAM을 사용하여 간단한 예제를 실습하는 기회로 삼겠습니다.
NS-NAM은 Network Simulator-Network AniMator의 약자로 네트워크 디자이너들과 석학들이 함께 모여 만든 소프트웨어 시뮬레이션 툴입니다. TcL(티클)이라는 스크립트를 작성하여 애니메이션 효과 또한 볼 수 있는 툴로써, 플랫폼에 상관없는 이식성과 C++ 클래스로의 확장성을 통해 쉽게 네트워크를 구현할 수 있습니다. 또한 x-graph 사용법을 추가하여 독자들이 만든 네트워크 디자인을 하드웨어의 구현 없이 분석할 수 있는 경험을 할 수 있을 것입니다.@
* 이 기사는 ZDNet Korea의 제휴매체인 마이크로소프트웨어에 게재된 내용입니다.





